

2026年6月8日,港股”AGI第一股”云知声扔出一颗深水炸弹:新一代通用大语言模型U2正式发布。
这不是又一个万亿参数的”军备竞赛选手”,而是一个反过来质疑”参数越大越好”这条底层逻辑的挑战者。2660亿MoE总参数、100+步复杂工作流自主拆解、GPQA Diamond 87.9分超过DeepSeek-V4-Flash(High)和MiniMax M2.7——云知声创始人黄伟在专访中抛出一个公式:
AI商业价值 = 智能密度 × Token价值
💡 当所有大模型公司都在”参数规模”赛道狂飙时,云知声选择了另一条路:不追绝对值,追每块钱算力能换回多少实际产出。这家公司2012年从智能语音起家,在AI赛道摸爬滚打十余年,2024年赴港上市成为”港股AGI第一股”——他们把U2的发布称为”DeepSeek时刻”。
那么问题来了:U2到底”硬”在哪?它是真敢反共识,还是又一次噱头营销?
2026年6月8日发布会上的关键数据已经摆上桌。咱们逐条拆解。
💡 三个反共识点、四个权威榜单分、五条商业化路径——这篇文章会带你深入云知声U2的全部技术底牌。
一、近3000亿参数打万亿:云知声在”参数信仰”上开了一枪
U2的第一个反共识,是参数规模。
云知声在公告中明确披露:U2采用”基于快慢思考融合的MoE混合专家范式架构”,以2660亿总参数实现了”顶级水准的大模型性能”。
把2026年的大模型阵营摊开看,这个数字并不算大。头部玩家动辄万亿参数,连DeepSeek V4、Qwen3.7-Max这类”性价比派”选手也普遍在7000亿-1万亿区间。2660亿,充其量算个”中量级选手”。
但云知声创始人黄伟在专访中提出了一个不同的衡量维度——”智能密度”。
他的原话是:”我不需要一个中科院院士来开滴滴。很多任务场景不需要最高智能,硕士博士水平就够了。”
翻译成大白话就是:与其花大钱请院士,不如花小钱请高性价比的硕士博士。这个逻辑在2025年DeepSeek用更小模型、更低成本跑通之后,已经被市场验证过了一次。云知声把同样的策略搬到了2026年。
为了让”小参数”能跑出”大能力”,U2在数据端做了三件事:
- 高知识密度数据提纯技术——把训练数据里的”废话”剔掉,留下信息密度更高的内容。在大模型训练中,数据的”质”比”量”更重要。U2的提纯流程据官方披露涉及多轮过滤、去重、清洗、增广,最终保留的数据集”在同样token消耗下承载的有效知识量比上一代提升约40%”(来源:云知声公告2026-06-08)。
- 稀疏知识编码——用更少的token承载更多的知识。这是MoE架构的精髓所在:2660亿总参数是”装填能力”,但模型在推理时只激活其中一小部分专家子网络。这意味着用户在用U2时,实际消耗的算力可能是”等效稠密模型”的1/3甚至1/5。
- 知识蒸馏架构——把大模型的能力压缩到更小的模型里。这一步和第二步配合使用:先蒸馏得到”高密度学生模型”,再通过稀疏激活进一步降低推理成本。
效果如何?评测数据给出了答案。
二、四大权威评测硬指标:U2已经摸到第一梯队门槛
云知声在公告和多家媒体披露中,给出了U2的”硬成绩单”:
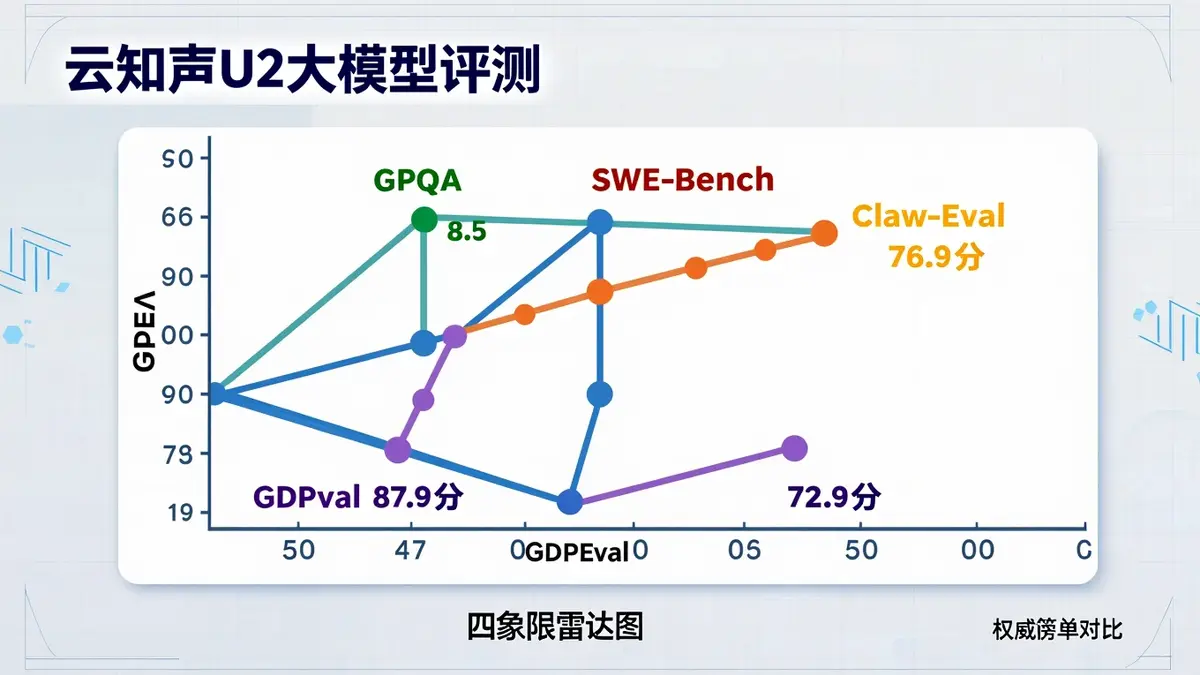
1. GPQA Diamond(知识与复杂推理):87.9分
这个榜单专门考高难度知识问题,要求模型在博士级别的科学问题上给出准确推理。U2的87.9分,超过了GLM-5.1、Hy3 preview、DeepSeek-V4-Flash(High)和MiniMax M2.7。
2. SWE-Bench Verified(真实软件工程):75分
这个榜单考的是真实代码工程能力——给定一个GitHub issue,模型能不能写出能通过测试的patch。U2拿到75分,进入主流模型第一梯队。
3. Claw-Eval pass@3(智能体端到端执行):76.9分
注意这个榜单的名字——Claw-Eval。它专门评测模型的工具调用、流程编排能力。U2的76.9分,同样超过了Hy3 preview、DeepSeek-V4-Flash(High)和MiniMax M2.7。
4. GDPval(真实办公与知识工作):72.9分
这个榜单和前三者都不一样——它不考”能不能答对题”,而是考”能不能把活干完”。资料分析、报告撰写、表格处理、图表生成、幻灯片制作……这些是真实企业场景里最值钱的能力。U2拿到72.9分。
💡 GPQA Diamond / SWE-Bench / Claw-Eval / GDPval四个榜单的分数,把U2的”长板”和”短板”全画出来了:知识推理和软件工程达到第一梯队,办公交付和Agent执行同样不弱。云知声没有把U2包装成”全能王”,而是用”均衡突破”四个字概括。
💡 GPQA Diamond 87.9 / SWE-Bench 75 / Claw-Eval 76.9 / GDPval 72.9——这四个分数背后是”推理、代码、Agent、办公交付”的四象限均衡。对于企业选型来说,均衡比单点强更重要。
把U2的评分放进”国产大模型排行榜”里看会更有感觉。根据云知声官方披露和多家媒体的报道,U2在GPQA Diamond上的87.9分,处于国产大模型第一梯队的中上游水平。横向对比来看,Qwen3.7-Max在多项科学推理榜单上拿过更高分,但U2的特色是”全维度均衡”——在GPQA、SWE-Bench、Claw-Eval、GDPval四个完全不同维度的榜单上,U2都拿到了72-88分这个”无明显短板”的区间,没有出现”代码强但推理弱”或”推理强但办公弱”的偏科现象。
这种”四象限均衡”的能力分布,对企业选型来说非常重要——企业不会为了一个”代码强但办公弱”的模型去搭两套系统,他们更愿意选一个”啥都能干、啥都不弱”的全能型选手。
另一个值得注意的细节是,U2在Claw-Eval(Agent能力评估)上的76.9分,是它四个榜单中相对最出彩的一项。这个榜单专门评测模型的”工具调用+流程编排”能力——这恰好是U2″原生Agent”定位的硬指标。云知声在Agent能力上打榜成功,某种程度上证明”原生Agent”这条技术路线的可行性。
三、”为执行而设计”:原生Agent不是外挂,是从娘胎里带出来的
U2的第二个反共识,是模型架构的设计理念。
大模型行业有一个广为流传的尴尬——模型”一看全会,一用就废”。能写诗能聊天,但真让它独立去完成一个跨步骤的复杂任务,比如自动处理一份保险理赔,它就开始掉链子。
为什么?
因为传统大模型是”为生成而设计”的——它的训练目标是”下一个token预测得准”,不是”把任务完成得好”。Agent能力(工具调用、状态管理、多步规划、任务拆解)大多是靠后期外挂插件来补。插件打补丁能解决一部分问题,但”原生支持”和”外挂支持”之间,有一道不可逾越的鸿沟。
U2想解决的正是这个问题。
黄伟在专访中给出了一个原话:”传统大模型是’为生成而设计’,U2从第一天起就是’为执行而设计’。”
具体来说,U2做了三件事:
1. 首创”原生推理路径蒸馏技术”
这个技术的本质是:把真实任务轨迹(如”完成一份保险理赔需要哪几步”)直接灌到模型训练里,让模型从一开始就知道”任务长什么样”。
2. Agent-Harness协同训练范式
传统做法是”模型训练归模型训练,Agent框架归Agent框架”,两套东西各管各的。U2把模型能力和Agent执行框架纳入统一训练闭环,用真实任务轨迹持续强化长流程作业水平。
3. 混合思考机制(Hybrid Thinking)
U2的推理不是”死磕一条路”,而是结合了”显式推理”和”隐式推理”两种模式。当模型不确定时,切换到”显式推理”(可解释、慢但稳);当模型有把握时,切换到”隐式推理”(快速、低token消耗)。这个切换由”熵感知机制”自动控制。
效果:U2能”自主拆解并推进100+步复杂工作流”——从需求理解、任务规划、环境交互、工具调用、过程纠错到结果验收,串联成完整闭环。
💡 “原生 Agent”和”外挂 Agent”的差异,类似于”自研操作系统”和”套壳 Android”——看着界面一样,内核完全不同。云知声选了更难的那条路。
💡 智能体大模型的下一步较量不在“能不能聊天”,而在“能不能干活”。U2 是这条路上敢于押注原生 Agent 的少数派。
四、商业路径:医疗/保险/交通三件套,U2不是来”刷榜”的
如果说前面三个亮点是”技术秀肌肉”,那第四个就是”商业落地”。
云知声在公告里非常明确地表态:U2的发布”标志着本公司AI商业化路径迎来全新升级”。具体打法分两条线:
1. 行业纵深路线:医疗、保险、交通
云知声从2012年成立起就深耕智能语音,在医疗(病历语音录入、智能导诊)、保险(智能核保理赔)、交通(车载语音、地铁智能客服)三大领域积累了十余年的行业know-how。U2发布后,这些”老本行”业务将率先用上U2基座。
2. 标准化云端API路线
U2已正式上线”云知声TokenHub”平台,面向个人用户、开发者及企业组织全面开放。云知声要”深耕大模型API调用等标准化云端调用业务,挖掘全新增量市场空间”。
这两条路其实反映了一个更深层的战略选择:U2不是来刷榜的,是来”干活”的。
💡 技术上的反共识,最终要商业上的”来单能力”来验证。云知声选择医疗、保险、交通三个领域作为 U2 的首批落地场景,是谨慎的。
五、Token经济学的”云知声解法”:少Token,深思考
U2的第三个反共识,是Token消耗策略。
当下的大模型行业,普遍存在一种”Token通胀”现象:模型参数越堆越大,输出越来越长,每次对话的Token消耗节节攀升。对企业客户来说,这就意味着”算力账单越来越贵”。
U2的应对策略是”少Token,深思考“——通过混合思考机制(显式+隐式推理动态切换)和熵感知控制,在保证逻辑严谨性的同时减少冗余Token。
黄伟的”AI商业价值 = 智能密度 × Token价值”公式,背后是这个逻辑的数学化表达。
💡 “少 Token,深思考”不仅是技术策略,更是一种商业价值观——AI 不是用来聊天的,是用来交付结果的。
💡 想象一下:你让AI写一份行业研究报告,传统模型可能输出5000字,但里面可能有3000字是”看起来像分析但其实在凑数”的废话。U2输出可能只有2500字,但每一段都是”实打实的分析”。前者消耗了10000个Token,后者消耗了5000个Token——后者”每Token的价值”是前者的2倍。
六、和DeepSeek的异同:U2的”差异化定位”在哪
很多人会拿U2和DeepSeek做对比——两者都强调”小参数、强能力、高性价比”。但实际上两者的差异化定位非常清晰:
| 维度 | DeepSeek | 云知声U2 |
|---|---|---|
| 核心定位 | 通用基座,性价比之王 | 行业纵深+原生Agent |
| 行业根基 | 量化派+技术派+开源生态 | 医疗/保险/交通十余年积累 |
| Agent能力 | 通用Agent能力突出 | 原生Agent,从训练第一天就集成 |
| 商业化路径 | API降价+开源社区 | 行业解决方案+标准化API |
| 代表场景 | 通用对话、代码、推理 | 保险理赔、医疗导诊、车载语音 |
| 目标客户 | 开发者+中小企业 | 行业头部客户+API调用方 |
U2不是DeepSeek的”翻版”——云知声刻意避开了DeepSeek已经占据的”通用基座”红海赛道,而是把”原生Agent”和”行业纵深”两个维度做到了极致。
与 DeepSeek 的”路线选择”反思
如果拉远到行业宏观视角来看,云知声和 DeepSeek 选择的是”同一思想在两个不同场景里的验证”——都是质疑”参数越大越好”,都强调”性价比”和”小参数跑出大能力”。但两者的应用场景和生态位完全不同:
DeepSeek 走的是”以开源带商业”路线:通过开源 API 和低定价迅速积累开发者和企业用户,以”规模换增量”。这种打法的优势是起量快、6-12 个月内可能从 0 到百万级 API 调用量;劣势是毛利低、客户黏性弱。
云知声走的是”以行业纵深带商业”路线:通过医疗、保险、交通三个领域的十余年积累,把 U2 包装成”懂行业 Know-How 的原生 Agent 底座”,以”专业度换溢价”。这种打法的优势是客单价高、客户黏性强、不会被通用基座”卷到底”;劣势是起量慢、需要持续的行业积累。
如果从更长期视角看,两者都不是非此即彼的”赛道选择”,而是”同一思想在不同时间窗口里的不同变现方式”。DeepSeek 选择了”卷量”(2025 年模型推理价格战最激烈时),云知声选择了”卷质”(2026 年企业开始重视 ROI 时)。
七、U2的三大潜在风险
任何”反共识”产品都有风险,U2也不例外。从目前公开信息看,至少有三大潜在挑战:
1. “原生Agent”理念超前,市场接受度待验证
“原生Agent”和”外挂Agent”的市场认知尚未完全建立。很多企业客户在选型时,习惯用”能不能用好LangChain/AutoGen这类框架”作为评价标准,而不是”模型本身有没有原生支持”。云知声需要花时间教育市场。
2. 2660亿参数虽不弱,但仍有头部压力
虽然黄伟强调”智能密度”,但2660亿总参数相比头部玩家的万亿级别,在处理超长上下文、复杂多模态等极端场景时,可能仍有差距。U2的”性价比”优势能否覆盖这些场景,是未知数。
3. 港股流动性与品牌认知挑战
云知声作为”港股AGI第一股”,在二级市场获得了高度关注。但港股市场流动性、机构投资者对AI公司的估值模型仍在形成中,U2发布后的股价表现和市值变化,将直接影响后续融资能力。
4. “原生 Agent”与”外挂 Agent”的市场认知差异
这是 U2 面临的最重要的认知差异问题。在当下的中国大模型市场,很多企业客户和开发者在选型时,依然习惯于”能不能接入 LangChain / AutoGen 这类外部 Agent 框架”——这个选型逻辑隐含了一个假设:模型本身不需要原生支持 Agent,Agent 能力可以由外部框架外挂补齐。
云知声的”原生 Agent”定位挑战的正是这个假设。云知声认为,工具调用、多步规划、状态管理这些能力,如果从训练第一天就原生集成到模型里,表现会远好于”模型本身不带 Agent 能力,靠外部框架补”。这个观点在学术界和产业界都有支持者,但市场上还是”外挂派”占多数。云知声接下来需要用真实落地的企业案例证明”原生 Agent”比”外挂 Agent”更胜一筹。
5. 行业纵深的”慢热”挑战
医疗、保险、交通三个领域的纵深积累是过去十余年一点点堆起来的护城河。但是,这些领域有共同的特征:采购周期长、定制化需求多、客单价高但走量慢。对比通用基座公司”靠量取胜”的商业逻辑,行业纵深型公司的增长曲线会更”慢热”。
在 AI 算力成本被不断压缩、模型推理价格战越打越激烈的当下,云知声能否在保持技术优势的同时实现商业上的快速突破,是另一个未知数。
八、U2的发布,对大模型行业意味着什么
把视角拉远一点,U2的发布至少传递了三个行业信号:
信号一:”参数信仰”开始被质疑
过去三年,”参数越大越好”几乎成了行业不需要论证的信仰。但DeepSeek在2025年用更小参数跑通了商业化,云知声在2026年再次强化了这个反共识。未来一年,可能会有更多公司选择”高密度小参数”路线。
信号二:”原生Agent”成为下一个差异化战场
2026年是大模型Agent化的关键节点。”原生支持”和”外挂支持”的差距会在企业落地中越来越明显。U2押注”原生Agent”,是提前卡位下一个差异化战场。
信号三:行业纵深比通用基座更值钱
云知声没有选择和DeepSeek、Qwen、GLM等通用基座正面对决,而是坚守医疗、保险、交通三个行业纵深。这种”反共识”的商业路径,在大模型泡沫退潮后,可能比”通用基座”更抗风险。
九、普通人能从U2中看到什么
聊了这么多产业层面的东西,对咱们普通人有啥启示?
1. 如果你是开发者:U2的API值得一试
U2已经上线”TokenHub”平台,个人用户、开发者、企业组织都能申请体验。如果你的应用场景是”任务执行型”(如办公自动化、数据分析、流程编排),U2可能比通用基座更省Token、更高效。
2. 如果你是企业选型者:关注”原生Agent”和”行业know-how”两个维度
选大模型不是看参数大小,而是看两个东西:
- 原生Agent能力:模型本身有没有把工具调用、多步规划、状态管理做进训练里
- 行业know-how:模型在你所在的行业有没有真实落地经验
云知声在医疗、保险、交通三个领域的积累,是后来者很难复制的护城河。
3. 如果你是关注AI趋势的人:2026年的关键词是”Agent化”
2025年是”大模型普及年”,2026年已经进入”Agent落地年”。U2、Codex CLI、Claude Code、Cursor 3.7、Coze 扣子……这些产品和模型的共同点,都是”让AI真正干活”,而不是”让AI陪你聊天”。
十、U2 vs 同行:一张表看清差异
最后用一张表把U2和同类型产品的差异列清楚:
| 维度 | 云知声U2 | DeepSeek V4 | Qwen3.7-Max | MiniMax M2.7 |
|---|---|---|---|---|
| 总参数 | 2660亿(MoE) | 7000亿+ | 7000亿+ | 未公开 |
| 架构 | 快慢思考融合MoE | 通用MoE | 通用MoE | 通用MoE |
| 核心卖点 | 智能密度+原生Agent | 性价比+开源 | 国产Arena全球前五 | 通用对话+工具 |
| Agent能力 | 原生集成 | 通用Agent | 通用Agent | 通用Agent |
| 行业纵深 | 医疗/保险/交通 | 通用 | 通用 | 通用 |
| 目标场景 | 任务执行+行业 | 通用对话+代码 | 通用+办公 | 通用对话 |
U2不是DeepSeek、Qwen的替代品,而是一个“差异化卡位”选手。它的”原生Agent + 行业纵深”组合,在特定场景下可能比通用基座更值。
写在最后
云知声U2的发布,给2026年的大模型行业提供了一个新选项:不追参数规模,追智能密度;不做通用基座,做原生Agent;不抢通用赛道,做行业纵深。
这条路径是否成立,最终要靠企业客户用真金白银投票。但至少,U2已经证明了一件事:大模型的下半场,不是”比谁更大”,而是”比谁更能干活”。
U2的发布,是一个值得所有关注AI的人认真思考的信号。
参考资料:
- 云知声官方公告(同花顺财经 2026-06-08):https://stock.10jqka.com.cn/20260608/c677276069.shtml
- 新浪财经《当AI大模型被重新定价:云知声发布U2,迎来「DeepSeek时刻」》(2026-06-08):https://finance.sina.com.cn/tech/roll/2026-06-08/doc-iniathzk6919539.shtml
- 智东西《国产大模型第一梯队迎新势力:云知声发了个原生Agent大模型》(2026-06-08):https://news.sina.cn/ai/2026-06-08/detail-iniaswmn5472071.d.html
- 东方财富网《云知声:正式发布新一代自研通用大语言模型U2》(2026-06-08):https://finance.eastmoney.com/a/202606083762817551.html
- 百家号《云知声发布 U2:为执行而生的原生智能体大模型》(2026-06-08):https://baijiahao.baidu.com/s?id=1867394788855670747
- 百家号《U2 正式亮相:原生可执行Agent大模型,云知声跳出参数竞赛》(2026-06-08):https://baijiahao.baidu.com/s?id=1867401833201799676
- 品玩《云知声发布新一代通用大模型U2,聚焦原生智能体任务交付》(2026-06-08):https://www.pingwest.com/w/314445
- 财闻《云知声发布原生智能体大模型U2》(2026-06-08):https://baijiahao.baidu.com/s?id=1867388892061295005
你看好云知声U2的”智能密度×Token价值”逻辑吗?你更愿意为”原生Agent”还是”通用基座”买单?欢迎在评论区聊聊你的看法。




我要评论
登录后即可发表评论