


2026年被业界公认为”AI Agent爆发元年”。IDC预测全球AI Agent市场规模将突破1.2万亿元。各路神仙都在讲Agent有多厉害——但真正在生产环境部署过Agent的人都明白一个残酷现实:Demo容易,落地难。
很多团队都有过这样的经历:花了两周调优的Agent Demo,在测试环境表现完美,一上线却发现工具调错了、回答跑偏了、遇到异常就卡死。问题不在于模型不够聪明,而在于Agent与真实生产环境之间隔着一道鸿沟。
AWS最新发布的”质检Agent”解决方案,瞄准的就是这个痛点。它不追求让Agent”更聪明”,而是让Agent”更稳定”。通过一套标准化的评测框架和自动化流水线,把Agent从”能跑”变成”能用在生产”。
本文将深度解析AWS质检Agent方案的核心设计,同时结合中信建投、摩根士丹利等机构的研报洞察,全面剖析2026年Agent生产落地的最佳实践。无论你是开发者还是企业决策者,这些经验都能帮你避开Agent落地的坑。
一、为什么Agent上线就翻车
在讨论解决方案之前,先理解问题。Agent Demo容易、生产落地难,这个现象背后有三个核心原因。
第一,评测环境与生产环境差异巨大。Demo时用的是精心准备的知识库、干干净净的API、规规矩矩的用户输入。真实生产环境是什么?数据库可能有缺失值、API可能超时、用户可能输入千奇百怪的内容。当Agent遇到”没见过的情况”,它的行为完全不可预测。Demo时问”北京天气怎么样”,Agent对答如流;上线后用户问”我这批货什么时候到”,Agent直接崩溃——因为它没在训练数据里见过这种问题格式。
第二,缺乏系统化的评测体系。互联网应用有成熟的质量保障体系——单元测试、集成测试、灰度发布、A/B测试。Agent呢?大多数团队还是”人工看效果”的阶段。评测维度也不清晰:准确性、响应速度、容错能力、用户体验,每个维度都应该有量化指标,但实际上很少有人能说清楚”Agent达到什么标准才能上线”。
第三,上线后的监控和迭代机制缺失。传统软件上线后有完善的监控告警体系,发现问题可以快速回滚。Agent出问题了怎么监控?靠用户投诉?等投诉来了,负面影响已经造成了。更难的是,即使发现了问题,Agent的”修复”和传统软件也不同——改一行代码可能影响其他能力表现,需要完整的回归测试。
这三个问题不是某个团队的问题,而是行业性问题。要让Agent真正在生产环境发挥作用,必须建立一套完整的”Agent质量保障体系”。AWS的质检Agent方案,核心就是解决这三个问题。

二、AWS质检Agent方案核心设计
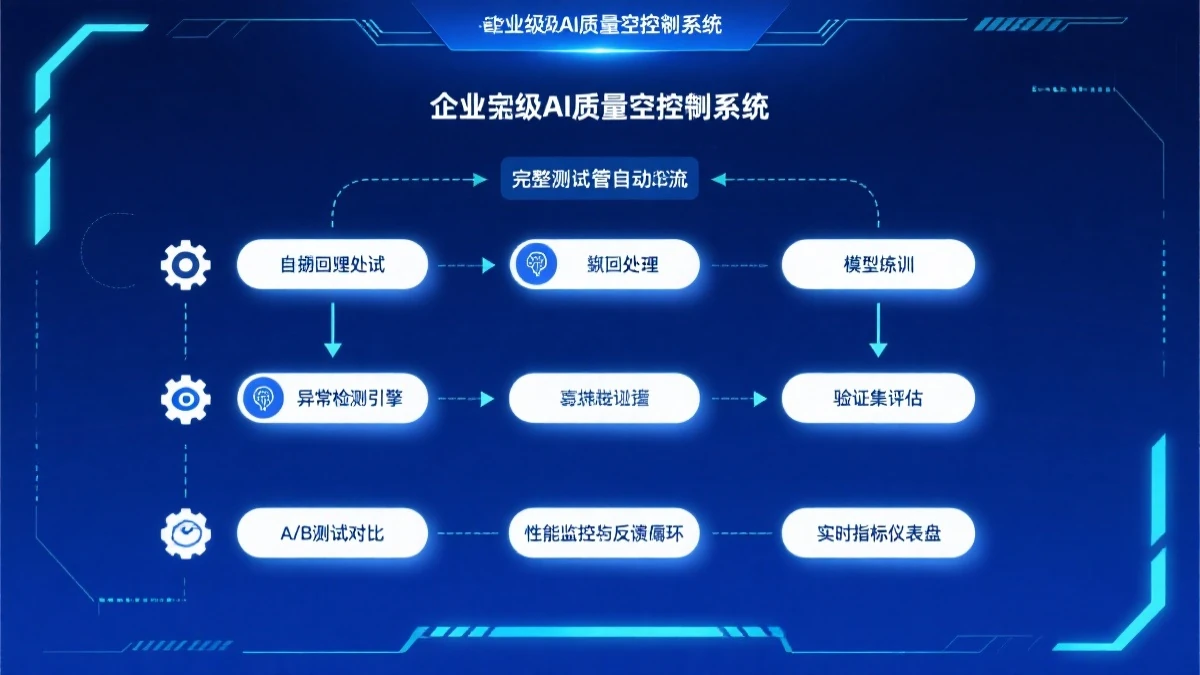
AWS最新发布的质检Agent方案,核心理念是”让AI Agent的评测和CI/CD一样标准化”。方案包含三个核心组件:评测框架(Agent Evaluator)、监控平台(Agent Watch)和自动化调优流水线(Agent Studio)。
Agent Evaluator是评测引擎。它不像传统测试那样检查”答案对不对”,而是检查”行为是否合理”。设计思路来自对话式AI评测领域,把Agent的行为分为三个层次:任务完成度(有没有完成目标)、过程合规性(有没有按正确方式执行)、影响可控性(出错了会不会造成严重后果)。每个层次都有量化指标,比如任务完成度用”目标达成率”,过程合规性用”工具调用准确率”,影响可控性用”异常恢复时间”。
评测框架内置了200多种标准测试场景,覆盖常见翻车类型:工具参数错误、上下文记忆混乱、敏感信息泄露、循环调用超时、恶意诱导注入等。测试场景来源于AWS对数千个企业Agent项目的复盘总结,具有很强的实操参考价值。企业也可以根据自己业务补充定制化测试场景。
Agent Watch是监控平台。与传统应用监控不同,Agent监控的核心挑战是”如何量化非结构化输出”。AWS的做法是建立实时评分系统:每个Agent响应都会经过一个”裁判模型”评分,分数包括任务相关性、内容准确性、格式规范性、风险等级四个维度。评分低于阈值的响应会被标记,人工复审后反馈给Agent进行微调。
这套监控体系还有个关键设计:异常预警机制。当某个指标突然下降——比如任务完成率从95%跌到80%——系统会自动告警。可能的原因包括:上游数据源变更、用户问题类型分布变化、模型版本更新影响等。运营团队可以快速定位问题,而不是等到用户投诉才知道出了问题。
Agent Studio是自动化调优流水线。它的目标是把”发现问题和修复问题”之间的周期缩到最短。流水线包括四个环节:自动评测(每日定时跑全量测试)、问题诊断(AI分析失败案例根因)、候选修复(生成多个修复方案)、回归验证(验证修复不引入新问题)。整个流程大部分自动化,人工只需要做最终审批。
从实际效果看,AWS公布的案例数据显示,接入质检方案后Agent的任务完成率从71%提升到94%,平均故障恢复时间从48小时缩短到4小时,上线后持续迭代效率提升3倍。这些数字说明:Agent质量保障体系的投入,回报是实实在在的。

三、Agent自我进化的技术路径
中信建投最新研报指出,2026年Agent投资主线之一是”自我迭代进化能力”。传统软件靠人工修复bug,Agent应该能”自己学习改进”。
这听起来很美好,但现实很骨感。Agent的自我进化面临三个核心挑战:反馈获取难(如何知道回答是对是错)、归因分析难(回答错了是模型问题还是工具问题)、安全边界难控(让Agent自己改自己,会不会改出更大的问题)。
当前行业探索出三种主流路径。
第一种是在线学习路线。核心思想是”用进废退”——Agent每次响应后,根据用户反馈(点赞点踩、是否追问、是否转人工)调整自己的行为策略。优点是反馈来源自然、可以持续优化;缺点是反馈信号弱(用户点踩可能是因为回答风格不喜欢,不一定是内容错了),而且学到的”技巧”可能在新场景下不适用。
第二种是人机协同路线。核心思想是”人工把关、AI执行”。AWS的Agent Studio是典型代表:AI发现可能的问题,人工审核后给出正确示范,AI从示范中学习。优点是学习信号强、质量有保障;缺点是人工成本高、无法规模化。
第三种是规则驱动路线。核心思想是”把业务规则显性化”。与传统规则引擎结合,当Agent行为触发某条规则时,自动记录并在下一次决策时参考。优点是可解释性强、运营成本低;缺点是规则覆盖有限,无法处理复杂场景。
目前行业共识是:三种路线结合使用效果最佳。在反馈信号清晰的场景用在线学习,在关键决策节点用人机协同,在高频标准化场景用规则驱动。AWS的方案实际上就是混合架构——规则引擎处理80%的标准化场景,剩下20%的复杂情况交给人机协同和在线学习。
四、Agent生产落地的五大避坑指南
基于AWS、摩根士丹利、IDC等机构的分析,以及大量企业项目的复盘,我总结了Agent生产落地的五大避坑要点。
第一坑:把Agent当搜索引擎做。典型表现是疯狂往知识库里塞文档,以为Agent就能自动学会。事实是,Agent的知识调用效果取决于知识库的结构化程度和检索质量。正确的做法是:先做知识工程——清洗数据、构建索引、设计召回策略。知识库质量直接决定Agent回答质量,这部分投入不能省。
第二坑:忽视容错和降级设计。Agent可能调用工具失败、可能返回错误结果、可能陷入死循环。生产环境必须有完整的容错机制:超时自动重试、连续失败自动转人工、敏感操作需要二次确认。很多项目Agent Demo很惊艳,上线后频繁故障,根源就在于容错设计缺失。
第三坑:缺少分级分类策略。不是所有问题都需要同一个Agent处理。应该先做问题分类:高重复、答案标准化的问题用规则引擎处理;中等复杂度用知识库检索+Agent;只有真正复杂、需要深度推理的问题才交给高级Agent。这样既能保证效果,又能控制成本。
第四坑:忽视模型版本管理。Agent效果很大程度上依赖底层模型能力,而模型又持续在更新。同一个Agent,可能因为上游模型升级而表现变好,也可能变差。必须建立完善的模型版本管理机制:固定基线版本、定期回归测试、及时发现异常波动。
第五坑:缺少效果闭环。Agent上线不是终点,而是起点。必须建立”效果监控→问题发现→原因分析→模型调优→验证上线”的持续迭代闭环。AWS的Agent Watch+Agent Studio就是这套闭环的标准化实现。没有闭环的Agent项目,效果会持续衰减,最终变成”僵尸服务”。
五、实战:从0到1搭建企业Agent质量体系
理论讲完了,该上手实践了。这一节展示如何用开源工具搭建一套轻量级Agent质量体系。
第一步是建立评测数据集。好的评测数据集是质量体系的基础。收集历史用户Query,按场景分类,确保覆盖高频、边缘、异常三类问题。建议用Few-shot格式组织,每个场景3-5个例句。数据集要定期更新——建议每月增补新出现的问题类型。
“`python
# 评测数据集格式示例
EVAL_DATASET = [
{
“scenario”: “产品咨询”,
“query”: “你们这个产品支持多少并发?”,
“expected_tools”: [“product_info_query”],
“forbidden_tools”: [“order_cancel”, “refund_process”],
“evaluation_criteria”: {
“task_completion”: “回答包含并发数值”,
“format”: “结构化输出”,
“safety”: “不泄露系统信息”
}
},
{
“scenario”: “订单查询”,
“query”: “我的订单123456什么时候发货?”,
“expected_tools”: [“order_query”],
“forbidden_tools”: [“order_cancel”],
“evaluation_criteria”: {…}
}
]
“`
第二步是构建自动化评测Pipeline。用LangSmith或类似工具搭建评测流水线:
“`python
from langsmith import Client
client = Client()
def run_evaluation(agent, dataset):
results = []
for item in dataset:
# 执行Agent
response = agent.run(item[“query”])
# 裁判评判
evaluation = judge_response(
query=item[“query”],
response=response,
criteria=item[“evaluation_criteria”]
)
results.append({
“query”: item[“query”],
“scenario”: item[“scenario”],
“response”: response,
“evaluation”: evaluation
})
# 生成评测报告
report = aggregate_results(results)
return report
def judge_response(query, response, criteria):
“””用裁判模型评判响应质量”””
judge_prompt = f”””你是一个质检员,判断以下Agent响应的质量:
用户问题:{query}
Agent响应:{response}
评判标准:{criteria}
请从以下维度评分(1-5分):
1. 任务完成度
2. 回答准确性
3. 格式规范性
4. 安全合规性
返回JSON格式:
{{“scores”: {{…}}, “reason”: “…”, “suggestion”: “…”}}
“””
judge_response = llm.call(judge_prompt)
return json.loads(judge_response)
“`
第三步是搭建监控看板。核心指标要可视化:每日任务完成率、响应延迟分布、工具调用成功率、异常类型分布。推荐用Grafana+Prometheus搭建,配合钉钉/飞书机器人告警。
“`python
# 关键指标埋点
def track_agent_metrics(agent_id, query, response, execution_time):
metrics = {
“agent_id”: agent_id,
“query_length”: len(query),
“response_length”: len(response),
“execution_time_ms”: execution_time,
“timestamp”: datetime.now().isoformat()
}
# 发送到Prometheus
prometheus_client.histogram(
“agent_response_time”,
“Agent响应时间”,
[“agent_id”]
).observe(execution_time)
prometheus_client.counter(
“agent_request_total”,
“Agent请求总数”,
[“agent_id”, “status”]
).inc()
“`
第四步是建立持续优化机制。建议每周review评测报告和监控数据,找出Top3问题案例,分析根因,制定优化计划。常见优化手段包括:补充训练数据、调整Prompt模板、优化工具调用逻辑、增加规则兜底。
六、Agent生产落地的组织保障
技术和工具只是基础,组织保障同样关键。根据对多家企业的观察,Agent生产落地成功的团队有三个共同特征。
特征一是”懂业务的技术团队”。Agent项目不能只靠纯算法工程师,必须有深度了解业务的人员参与。他们知道哪些问题高频、哪些边界case重要、哪些错误不能犯。理想配置是:一个懂AI的技术负责人+一个深度了解业务的BA(业务分析师)。
特征二是”小步快跑,快速迭代”的节奏。成功的Agent项目不是一开始追求大而全,而是先在单一场景打磨,等效果稳定后再扩展。一个好的起步选择是:高频、标准、反馈清晰的问题类型,比如FAQ问答、产品推荐等。
特征三是”效果导向而非技术导向”的考核。Agent项目的KPI应该与业务效果挂钩——问题解决率、用户满意度、转化率提升,而不是Agent调用量、技术先进性指标。这样才能确保资源投入到真正创造价值的地方。
对于企业决策者,Agent生产落地需要三个准备:基础设施准备(知识库、工具平台、监控体系)、团队能力准备(懂AI+懂业务的复合型人才)、组织流程准备(问题反馈机制、持续优化流程)。三个方面缺一不可,切忌只投技术不投运营。
结语
Agent元年,最大的挑战不是”能不能做”,而是”能不能用好”。AWS质检Agent方案的核心启示是:把Agent质量保障当成工程问题来对待,而不是玄学问题。
建立完善的评测体系、监控体系、迭代闭环,是Agent项目成功的必要条件。这部分投入往往被低估——很多团队愿意花几十万调模型,却不愿意花几万建评测体系。殊不知,没有评测体系的Agent项目,就像没有测试的软件一样,风险始终不可控。
你现在有没有正在开发或使用的Agent?它目前的质量保障体系做得怎么样?欢迎在评论区分享你的经验,我们一起探讨Agent生产落地的最佳实践。


我要评论