【进阶实战】Day12:向量数据库——RAG的基石
如果把RAG系统比作一家餐厅,那么向量数据库就是它的”中央仓库”。想象一下,一位厨师(LLM)需要根据顾客的订单(用户问题)从仓库里取出最新鲜的食材(相关文档)来烹饪。仓库管理得越好、食材分类越清晰,厨师就能越快找到所需材料,烹饪出的菜品也就越精准美味。
这正是向量数据库在RAG架构中的核心价值:它以极其高效的方式存储和检索”知识的向量表示”,让大模型能够在海量信息中瞬间锁定最相关的上下文。毫不夸张地说,没有向量数据库,RAG就像没有了图书馆的索引系统——你只能逐页翻阅整本书来找一个答案。
今天这篇文章,我们将深入探讨向量数据库的工作原理、主流产品对比、核心操作流程,以及在RAG系统中的实战应用技巧。无论你是AI开发者、知识库架构师,还是对RAG技术充满好奇的学习者,这篇教程都将为你打下坚实的向量数据库基础。
一、为什么RAG需要向量数据库
在正式介绍向量数据库之前,我们需要先理解一个根本性问题:为什么RAG系统不能简单地用传统关系型数据库(比如MySQL)或全文检索工具(比如Elasticsearch)来存储文档?
答案藏在”语义理解”四个字里。
1.1 传统检索的局限性
传统数据库和全文检索系统依赖的是关键词匹配或精确查询。当你搜索”苹果”时,系统会返回所有包含”苹果”这个词的文档,但它无法理解你指的是水果苹果、手机苹果,还是这家科技公司。
举例来说,如果用户问:”iPhone的续航能力如何提升?”传统检索可能会返回包含”iPhone”、”续航”、”提升”这些词的文章。但问题是,关于”延长手机电池使用时间”的技巧文章虽然语义相关,却可能因为没有同时包含这三个关键词而被遗漏。
这就是”一词多义”和”多词一义”带来的根本性困境。传统检索只能捕获字面意思,无法捕捉语言的深层语义。
1.2 向量检索的革命性突破
向量数据库的核心创新在于,它将文本、图像、音频等任何形式的数据转换为高维向量——一种数字列表——然后通过向量相似度来判断语义关联性。
当”iPhone续航提升”和”延长手机电池使用时间”这两句话被转换为向量后,它们的向量表示会非常接近,因为它们传达的核心含义是相似的。这意味着,即使没有任何共同的关键词,系统也能识别出它们之间的语义关联。
向量数据库正是利用了这种”语义相似度”来检索信息。它不再追求”找到完全匹配的关键词”,而是”找到意思最相近的内容”。
1.3 海量数据下的性能需求
RAG系统需要处理的数据规模往往非常庞大。一个企业知识库可能包含数十万份文档;一个垂直领域的语料库可能涵盖数亿个网页。在这样的数据规模下,即使是语义检索也需要在毫秒级时间内返回结果。
传统数据库的精确匹配和倒排索引在简单场景下表现尚可,但面对高维向量的相似度计算时,性能会急剧下降。而向量数据库从设计之初就考虑了这个问题,采用近似最近邻(ANN)算法,能够在保证足够精度的前提下,将检索速度提升几个数量级。
向量数据库能够实现:
- 十亿级向量毫秒检索:通过HNSW、IVF等索引技术实现极速相似度搜索
- 分布式水平扩展:数据增长时只需添加更多节点,无需重构系统
- 混合检索能力:同时支持向量检索和传统关键词检索
这三点正是RAG系统在生产环境中必须选择专业向量数据库的原因。
向量数据库核心架构:从文本到向量的转换与检索流程
二、向量的本质:数字世界里的”语义坐标”
要理解向量数据库的工作原理,我们首先需要理解什么是”向量”——这个看似抽象的数学概念,其实可以用一个熟悉的比喻来解释。
2.1 向量即”语义坐标”
想象一个二维坐标系,X轴代表”水果→电子产品的跨度”,Y轴代表”具体→抽象的程度”。当我们把”苹果”(水果)放在左下角,把”iPhone”(电子产品)放在右下角,把”营养价值”(抽象概念)放在左上角,把”续航能力”(具体属性)放在右上角时,语义相近的词汇在坐标系中的距离就会更近。
这个坐标系中的每个点就是一个向量。只不过真实的向量维度不是二维,而是768维、1024维,甚至更高。维度越高,能表达的语义细节就越丰富,但计算成本也越高。
以OpenAI的text-embedding-3-large模型为例,它生成的向量有3072个维度,每个维度代表一个语义特征。当你说”如何延长手机电池寿命”时,系统会先把这句话转换为3072维空间中的一个点,然后找出距离这个点最近的N个点——这些点对应的就是语义最相关的文档。
2.2 向量嵌入的实现方式
把文本转换为向量的过程叫做”嵌入”(Embedding)。这个过程通常由专门的嵌入模型完成,常见的嵌入模型包括:
OpenAI系列:
- text-embedding-3-small:1536维,轻量快速
- text-embedding-3-large:3072维,精度更高
开源系列:
- BGE(BAAI General Embedding):中文优化,支持多语言
- M3E(Moka Mixed Embedding):专为中文场景设计
- Instructor(西湖大学出品):可针对特定领域微调
不同的嵌入模型在精度、速度、语言支持方面各有侧重。中文场景下,BGE和M3E是开源社区最常使用的选择。
2.3 相似度度量:如何判断”像不像”
向量数据库判断两个向量是否相似,需要借助”相似度度量算法”。最常用的三种算法是:
余弦相似度(Cosine Similarity):计算两个向量夹角的余弦值,取值范围从-1到1。夹角越小,余弦值越接近1,表示越相似。在文本检索场景中,余弦相似度是最常用的选择,因为它对向量的长度不敏感,更关注方向性。
点积(Dot Product):两个向量对应元素相乘后求和。取值范围不限,值越大表示越相似。点积计算速度快,但在向量长度差异较大时可能不够稳定。
欧氏距离(Euclidean Distance):计算两个向量在几何空间中的直线距离。距离越小,表示越相似。欧氏距离适合需要考虑向量大小的场景,但在高维空间中可能出现”维度灾难”问题。
在RAG系统的实际应用中,余弦相似度是最普遍的选择,因为它能更稳定地处理不同长度文本的嵌入向量。

主流向量数据库产品功能对比:Milvus、Pinecone、Weaviate、Chroma
三、主流向量数据库深度对比
当前市场上存在多种成熟的向量数据库产品,它们在设计哲学、功能特性、性能表现和成本结构上各有差异。接下来的内容将帮助你根据实际需求做出正确的技术选型。
3.1 Milvus:开源界的标杆
Milvus是目前最流行的开源向量数据库,GitHub星标超过43,600颗,被广泛应用于国内外各大企业的生产环境。
核心优势:
- 完全开源,支持私有化部署,数据完全不离开你的服务器
- 支持十亿级向量规模,配备HNSW、IVF-PQ等多种索引类型
- 分布式架构天然支持水平扩展,从单节点到大规模集群只需配置变更
- 提供了Python、Go、Java等多种语言的SDK,以及完善的RESTful API
- 与主流AI框架(LangChain、LlamaIndex)深度集成
适用场景:
- 对数据安全和隐私有严格要求的企业(如金融、医疗、政府领域)
- 需要处理超大规模向量数据的场景(如互联网内容检索、推荐系统)
- 拥有技术团队能够进行运维管理的组织
云服务选项:
Zilliz Cloud是Milvus的官方托管服务,提供了完全管理的云版本。如果你不想自己运维集群,但又希望使用Milvus的能力,Zilliz Cloud是最佳选择。其免费 tier提供36万个向量存储,对于中小规模应用来说完全够用。
3.2 Pinecone:云原生的便捷之选
Pinecone是专为开发者打造的云原生向量数据库,以”5分钟上手”为卖点,在易用性方面下足了功夫。
核心优势:
- 完全托管服务,零运维负担——不需要配置服务器、不需要关心索引优化
- 自动扩展能力,流量高峰时无需人工干预
- 提供内置的命名空间(Namespace)和分区(Partition)功能,方便数据隔离
- 丰富的内置过滤能力,支持在向量检索时进行元数据过滤
- 延迟稳定,SLA保障达到99.9%
适用场景:
- 快速启动阶段,希望尽快验证想法的创业团队
- 技术团队规模小、缺乏专职运维人员的公司
- 对稳定性要求高、需要SLA保障的生产环境
成本考量:
Pinecone采用按存储量和查询次数计费的模式。免费版提供100万向量存储和20万次查询,对于个人开发者和小型项目来说非常友好。生产环境的费用根据所选规格不同,每月从几十美元到上千美元不等。
3.3 Weaviate:知识图谱与向量检索的融合
Weaviate的独特之处在于它将向量检索与知识图谱能力深度融合,为需要处理复杂实体关系的场景提供了原生支持。
核心优势:
- 原生支持知识图谱结构,实体和关系都可以作为向量存储
- 同时支持向量检索和结构化查询(GraphQL-like API),可以混合使用
- 内置向量化模块(text2vec-transformers),无需自行部署嵌入模型
- 提供了丰富的开箱即用模块,包括问答系统、分类器、NER等
适用场景:
- 需要同时管理结构化数据和向量数据的应用
- 构建企业知识图谱或智能问答系统
- 希望用单一数据库解决多种AI场景的开发者
3.4 Chroma:轻量级嵌入式数据库
Chroma是专为AI应用设计的轻量级向量数据库,Python-first的设计理念让它成为个人开发者和快速原型开发的首选。
核心优势:
- 零配置、零依赖——pip install后直接使用
- 专为Python设计,提供简洁直观的API
- 可以作为嵌入式数据库运行,也可以切换到客户端-服务器模式
- 非常适合学习和实验场景
局限性:
- 不适合大规模生产环境,单节点性能有限
- 缺乏分布式和水平扩展能力
- 云服务支持相对薄弱
适用场景:
- 个人项目、原型验证、机器学习实验
- 数据量在百万级以下的小规模应用
- 学习和研究目的的向量检索实验
3.5 主流产品对比一览
[TABLE_PLACEHOLDER]
| 数据库 | 开源协议 | 规模能力 | 云服务 | 学习曲线 | 推荐指数 |
|---|---|---|---|---|---|
| Milvus | Apache 2.0 | 十亿级 | Zilliz Cloud | 中等 | ⭐⭐⭐⭐⭐ |
| Pinecone | 商业闭源 | 十亿级 | 原生支持 | 简单 | ⭐⭐⭐⭐ |
| Weaviate | BSD | 亿级 | Weaviate Cloud | 中等 | ⭐⭐⭐⭐ |
| Chroma | Apache 2.0 | 百万级 | 无 | 极简 | ⭐⭐⭐ |
如果你是企业级用户、追求数据自主可控,Milvus是最佳选择。如果你想快速启动、不想操心运维,Pinecone的体验最为顺畅。如果你的应用涉及复杂的实体关系,Weaviate的知识图谱能力会让你眼前一亮。如果你是个人开发者或只是做实验,Chroma的轻量会让你爱不释手。
四、向量数据库的核心操作
了解了不同产品的特点后,我们需要掌握向量数据库的基本操作能力。无论选择哪款产品,以下四类操作都是核心:增、删、改、查。
4.1 向量插入:构建你的知识库
向量插入是将文本或其他数据转换为向量并存储到数据库中的过程。这个过程通常包含以下步骤:
第一步:文档预处理。原始文档需要经过清洗和分块(Chunking)处理。分块策略直接影响检索效果——块太大,包含了太多无关信息,增加计算负担且稀释关键信息;块太小,可能丢失必要的上下文,导致答案不完整。
常见的分块策略包括:
- 固定长度分块:按字数或token数均匀切分,实现简单但可能切断语义连贯性
- 句子级别分块:按句子边界切分,保证语义完整性但块大小不均匀
- 段落级别分块:保留段落完整性,适合结构化文档
- 递归分块:按层级结构递归切分,先大块再小调,兼顾完整性和均匀性
第二步:生成向量嵌入。使用选定的嵌入模型将每个文本块转换为向量表示。这一步是整个流程中计算量最大的部分,通常也是性能瓶颈所在。
第三步:存储到向量数据库。将原始文本块(作为元数据)和对应的向量一起存储到数据库中。元数据非常重要——它让我们能够在检索时获取完整的原始文本内容。
4.2 向量查询:找到最相似的N个结果
向量查询是根据用户问题找到最相关文档的过程。这个过程看似简单,背后却涉及复杂的算法优化。
Top-K检索:用户问题被转换为向量后,系统需要在数据库中找到距离最近的K个向量。这K个向量对应的文档就是最终返回给大模型的上下文。
近似最近邻算法(ANN):精确计算所有向量距离的时间复杂度是O(N),在十亿级数据下完全不可行。ANN算法通过建立索引结构,将时间复杂度降低到O(log N)甚至O(1),代价是略微降低检索精度。主流的ANN算法包括:
- HNSW(Hierarchical Navigable Small World):基于图的索引,在召回率和延迟方面表现均衡,是目前最流行的选择
- IVF(Inverted File Index):基于聚类的索引,通过先定位聚类中心再在类内搜索的方式提升效率
- PQ(Product Quantization):通过向量压缩大幅降低内存占用,适合超大规模数据场景
重排序(Rerank):ANN算法返回的结果是”近似最优”而非”精确最优”。在RAG系统中,通常会在ANN初筛后,用更精确的算法(如密集检索)对Top-K结果进行重新排序,以提升最终答案的相关性。
4.3 元数据过滤:精准筛选目标范围
在实际应用中,我们经常需要在向量检索的基础上增加筛选条件。比如在企业知识库中,用户可能只希望搜索”2024年以来的财务报告”,或者”某个特定部门的技术文档”。
向量数据库通过元数据过滤来实现这一能力。在存储向量时,可以为每个向量附加任意的键值对作为元数据。查询时,系统会先根据向量相似度找到候选集,再在候选集内根据元数据条件进行二次筛选。
一个典型的过滤查询场景:
- 条件:department=”技术部” AND year>=2024 AND status=”已发布”
- 先执行向量检索得到Top 100候选
- 再在候选中筛选出满足元数据条件的最终结果
需要注意的是,过滤条件会直接影响检索性能。如果过滤后的结果数量很少,系统可能需要检索更多的向量来补充。合理设计元数据结构,避免过度依赖过滤,是保持检索性能的关键。
4.4 向量更新与删除:保持数据的时效性
知识库中的内容并非一成不变。新文档需要添加,过时内容需要删除,信息变更需要更新。向量数据库需要高效地支持这些动态操作。
添加操作相对简单,新向量直接追加到现有数据集中,索引会自动更新以包含新数据。大多数向量数据库的添加操作可以在毫秒级完成。
删除操作需要分两种情况讨论。软删除是在向量中设置一个”已删除”标记,查询时自动过滤,适用于需要保留审计轨迹的场景。硬删除则是物理移除向量数据,释放存储空间,但可能导致索引结构的重新调整。
更新操作在向量数据库中的处理方式通常是”删除+添加”的组合。因为向量的高维性质,单个向量的部分修改几乎不存在——语义一旦改变,通常意味着生成全新的向量。
对于需要频繁更新的场景(如实时性很强的应用),建议采用”写时复制”策略:新版本作为新向量存储,旧版本标记为过期,查询时只返回最新版本的结果。
五、在RAG系统中构建向量知识库
理论讲完了,接下来进入实战环节。这一部分将手把手教你如何从零开始,在RAG系统中构建向量知识库。
5.1 环境准备与依赖安装
我们选择Milvus作为向量数据库,配合Python语言进行演示。首先安装必要的依赖包:
pip install pymilvus gradio pymilvus[model] langchain langchain-communitypymilvus是Milvus的Python客户端,model扩展包含了嵌入功能,langchain则是构建RAG系统的主流框架。
5.2 连接Milvus服务器
from pymilvus import MilvusClient
# 连接到Milvus服务
# 本地部署使用 uri="http://localhost:19530"
# 云服务使用 uri="https://xxx.zillizcloud.com:443"
client = MilvusClient(uri="http://localhost:19530")如果是首次使用,需要先启动Milvus服务。Docker是最简单的启动方式:
docker run -d --name milvus-etcd \
-p 2379:2379 \
-p 2382:2382 \
quay.io/coreos/etcd:v3.5.5 \
etcd -advertise-client-urls=http://127.0.0.1:2379,etcdURL
docker run -d --name milvus-minio \
-p 9000:9000 \
-p 9001:9001 \
minio/minio:RELEASE.2023-03-20T20-16-18Z \
minio server /minio_data --console-address ":9001"
docker run -d --name milvus \
-p 19530:19530 \
-p 9091:9091 \
--env ETCD_ENDPOINTS="milvus-etcd:2379" \
--env MINIO_ADDRESS="milvus-minio:9000" \
milvusdb/milvus:v3.0.05.3 创建Collection(集合)
在Milvus中,向量数据存储在Collection中,类似于关系数据库中的表。
from pymilvus import CollectionSchema, FieldDescription, DataType, Collection
# 定义Collection的Schema
# 每个Collection需要指定向量字段的名称和维度
fields = [
FieldDescription(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldDescription(name="content", dtype=DataType.VARCHAR, max_length=65535),
FieldDescription(name="vector", dtype=DataType.FLOAT_VECTOR, dim=1024),
FieldDescription(name="source", dtype=DataType.VARCHAR, max_length=512),
FieldDescription(name="create_time", dtype=DataType.INT64)
]
schema = CollectionSchema(fields=fields, description="RAG Knowledge Base")
collection = Collection(name="rag_knowledge_base", schema=schema)对于中文嵌入模型BGE,向量维度通常为1024维。如果是OpenAI的text-embedding-3-large,则需要3072维。
5.4 文档分块与向量化
接下来,我们来实现文档的分块和向量化。
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
# 初始化分块器
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 每个块约500字
chunk_overlap=50, # 块之间50字的 overlap,保持上下文连贯
length_function=len,
separators=["\n\n", "\n", "。", "!", "?", ",", " ", ""]
)
# 初始化嵌入模型(使用BGE中文模型)
embeddings = HuggingFaceBgeEmbeddings(
model_name="BAAI/bge-large-zh-v1.5",
model_kwargs={"device": "cuda"},
encode_kwargs={"normalize_embeddings": True}
)
def process_document(documents: list[str], metadata: list[dict]):
"""处理文档列表,返回向量和元数据"""
vectors = []
contents = []
sources = []
for doc, meta in zip(documents, metadata):
# 分块
chunks = text_splitter.split_text(doc)
for chunk in chunks:
# 生成向量
vector = embeddings.embed_query(chunk)
vectors.append(vector)
contents.append(chunk)
sources.append(meta.get("source", "unknown"))
return vectors, contents, sources5.5 插入数据与构建索引
# 准备示例数据
documents = [
"RAG技术是一种结合检索和生成的AI架构。",
"向量数据库是RAG系统的核心组件。",
"Milvus是目前最流行的开源向量数据库。"
]
metadata = [
{"source": "article1.txt"},
{"source": "article2.txt"},
{"source": "article3.txt"}
]
# 分块和向量化
vectors, contents, sources = process_documents(documents, metadata)
# 插入数据
data = [
{"content": c, "vector": v, "source": s}
for c, v, s in zip(contents, vectors, sources)
]
collection.insert(data)
# 创建索引(必须步骤,否则查询性能极差)
index_params = {
"index_type": "HNSW", # HNSW是最常用的索引类型
"metric_type": "COSINE", # 余弦相似度
"params": {"M": 16, "efConstruction": 200}
}
collection.create_index(field_name="vector", index_params=index_params)
# 加载Collection到内存
collection.load()5.6 执行向量检索查询
数据准备就绪后,就可以开始查询了。
def search(query: str, top_k: int = 5):
"""执行向量检索"""
# 将用户问题转换为向量
query_vector = embeddings.embed_query(query)
# 搜索最相似的top_k个结果
search_params = {"metric_type": "COSINE", "params": {"ef": 128}}
results = collection.search(
data=[query_vector],
anns_field="vector",
param=search_params,
limit=top_k,
output_fields=["content", "source"]
)
return results
# 示例查询
query = "RAG系统需要哪些核心组件?"
results = search(query, top_k=3)
for i, result in enumerate(results[0]):
print(f"结果 {i+1}:")
print(f"内容: {result.entity.content}")
print(f"来源: {result.entity.source}")
print(f"相似度: {result.distance}")
print("---")5.7 带元数据过滤的查询
def search_with_filter(query: str, source_filter: str = None, top_k: int = 5):
"""带元数据过滤的向量检索"""
query_vector = embeddings.embed_query(query)
search_params = {"metric_type": "COSINE", "params": {"ef": 128}}
# 构建过滤表达式
expr = None
if source_filter:
expr = f'source == "{source_filter}"'
results = collection.search(
data=[query_vector],
anns_field="vector",
param=search_params,
limit=top_k,
expr=expr,
output_fields=["content", "source"]
)
return results
# 只搜索来自article1.txt的内容
results = search_with_filter("RAG技术", source_filter="article1.txt", top_k=3)六、向量数据库性能优化指南
在生产环境中,性能优化是永恒的话题。本部分将分享向量数据库调优的核心策略。
6.1 索引参数调优
HNSW是最常用的索引类型,它的两个核心参数直接影响性能:
M(邻居数):每个节点最多连接M个其他节点。M值越大,检索精度越高,但内存占用和构建时间也会增加。在精度和性能的权衡中,通常选择M=16~64。对于大多数场景,M=32是不错的默认值。
ef(搜索范围):查询时使用的动态列表大小。ef值越大,搜索的候选节点越多,精度越高,但延迟也会增加。通常设置ef为top_k的2~4倍。例如,如果需要返回top 10的结果,建议设置ef=40。
6.2 批量插入提升吞吐量
单条插入的效率很低,在构建知识库时应该使用批量插入:
# 批量插入(推荐)
batch_size = 1000
for i in range(0, len(all_vectors), batch_size):
batch_vectors = all_vectors[i:i+batch_size]
batch_contents = all_contents[i:i+batch_size]
batch_sources = all_sources[i:i+batch_size]
batch_data = [
{"content": c, "vector": v, "source": s}
for c, v, s in zip(batch_contents, batch_vectors, batch_sources)
]
collection.insert(batch_data)
print(f"已插入 {min(i+batch_size, len(all_vectors))} / {len(all_vectors)}")6.3 内存管理策略
向量数据库的性能严重依赖数据是否在内存中。对于超大规模数据,需要合理规划内存使用:
内存估算公式:向量数量 × 向量维度 × 4字节(float32)
以Milvus为例,1亿个1024维的向量需要约400GB内存。这个规模通常需要分布式部署。
数据冷热分离:将历史数据和最新数据分开存储,历史数据可以使用压缩率更高的索引(如PQ),最新数据保持高精度的HNSW索引。
6.4 混合检索策略
纯向量检索有时无法满足精准匹配的需求。实践中,常见的做法是结合BM25或稠密检索进行”混合检索”:
def hybrid_search(query: str, vector_weight: float = 0.7, top_k: int = 5):
"""混合检索:结合向量检索和关键词检索"""
query_vector = embeddings.embed_query(query)
# 向量检索
vector_results = collection.search(
data=[query_vector],
anns_field="vector",
param={"metric_type": "COSINE", "params": {"ef": 128}},
limit=top_k * 2, # 多取一些用于融合
output_fields=["content", "source"]
)
# 简单关键词匹配(可以用BM25替代)
keyword_results = [r for r in collection.query(
expr=f'content like "%{query}%"',
output_fields=["content", "source"]
)]
# 使用RRF(Reciprocal Rank Fusion)融合结果
fused_scores = {}
for rank, result in enumerate(vector_results[0]):
doc_id = result.id
fused_scores[doc_id] = fused_scores.get(doc_id, 0) + vector_weight / (rank + 1)
for rank, result in enumerate(keyword_results):
doc_id = result["id"]
fused_scores[doc_id] = fused_scores.get(doc_id, 0) + (1-vector_weight) / (rank + 1)
# 返回融合后的top_k结果
sorted_docs = sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)[:top_k]
return sorted_docs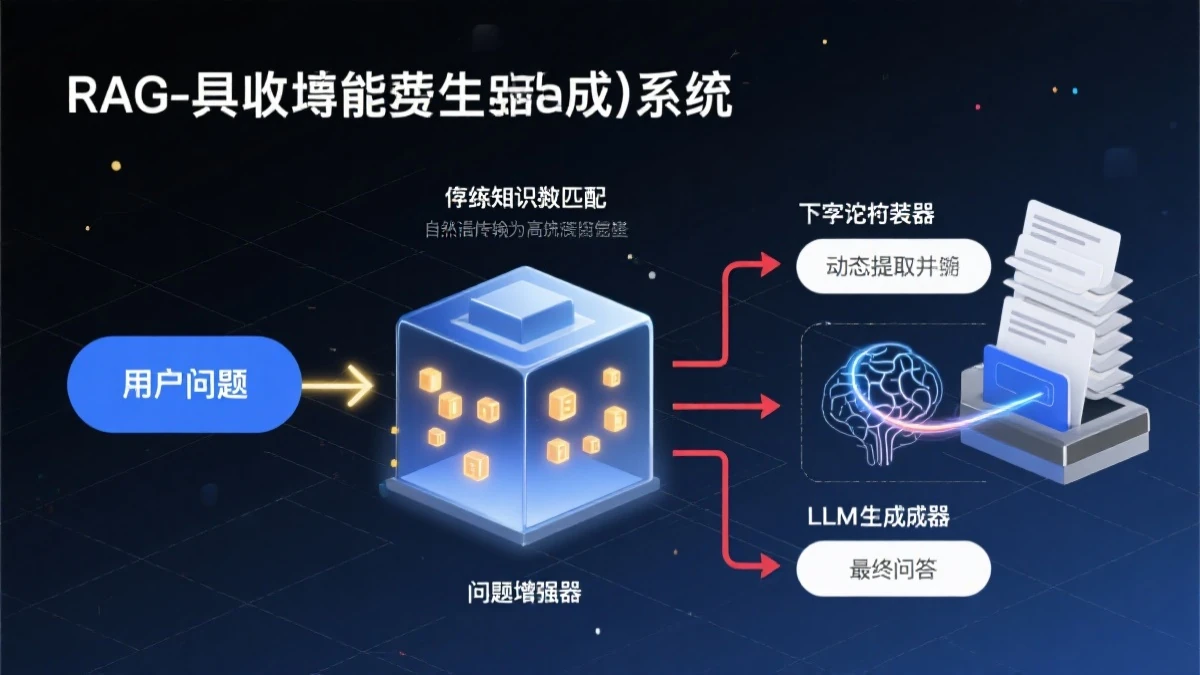
RAG系统完整检索流程:问题向量化→向量数据库检索→上下文组装→LLM生成
七、常见问题与解决方案
7.1 向量数据库占用内存过大怎么办
问题:随着数据量增长,Milvus占用的内存越来越大,甚至导致服务器崩溃。
解决方案:
1. 使用内存映射(MMap)将索引数据存储到磁盘,按需加载到内存
2. 切换到PQ量化索引,大幅降低内存占用(代价是略微降低精度)
3. 采用分区策略,将数据按时间或类别分散到多个Collection
4. 升级服务器配置或采用分布式部署
7.2 检索结果的相关性不高
问题:向量检索返回的结果看起来不太相关,即使语义上相近的内容也找不到。
排查步骤:
1. 检查嵌入模型是否适合你的数据类型(特别是中英文场景)
2. 调整分块大小——太大或太小都会影响效果
3. 尝试不同的相似度度量算法(余弦 vs 点积)
4. 检查索引参数是否合理,ef值是否过低
5. 考虑使用重排序(Rerank)模型对初筛结果进行二次排序
7.3 嵌入生成速度太慢
问题:文档向量化消耗大量时间,知识库构建进度缓慢。
优化方案:
1. 使用GPU加速嵌入计算(如BGE支持CUDA加速)
2. 并行处理多个文档(batch processing)
3. 考虑使用更轻量的嵌入模型(如text-embedding-3-small替代large)
4. 对于超大规模数据,可以使用分布式嵌入服务
7.4 如何保证检索结果的准确性
问题:RAG系统有时会返回错误或过时的信息。
最佳实践:
1. 定期更新知识库,删除或标记过时内容
2. 为每个文档添加时间戳和版本号元数据
3. 在查询时过滤掉时间过于久远的内容
4. 实现用户反馈机制,持续优化检索效果
5. 在RAG的生成阶段增加”置信度低时拒答”的逻辑
7.5 向量数据库如何选型
问题:Milvus、Pinecone、Chroma……到底该选哪个?
选型建议:
- 数据量大(千万级以上)、需要私有部署 → Milvus
- 想快速上线、不想运维 → Pinecone
- 个人项目或学习用途 → Chroma
- 需要知识图谱能力 → Weaviate
- 已在使用某个云厂商的服务 → 该厂商的向量数据库产品
八、总结与行动建议
今天的教程系统地介绍了向量数据库在RAG系统中的核心价值和工作原理。我们从”为什么RAG需要向量数据库”这一根本问题出发,深入探讨了向量表示的语义本质、干维向量检索的性能优势,以及Milvus、Pinecone等主流产品的特点对比。
在实战层面,我们完整演示了从环境搭建、文档分块、向量化、到索引构建和检索查询的全流程。性能优化和常见问题的章节,则帮助你在生产环境中避开的各种坑。
向量数据库是RAG技术栈的基石,选择合适的数据库产品、掌握核心操作、优化检索性能,这些都是构建高效RAG系统的必经之路。
今日行动建议:
1. 动手实验:使用Docker部署Milvus,运行本文的示例代码,感受向量检索的全流程
2. 对比选型:根据你的实际场景,对比2-3款向量数据库产品,从性能、功能、成本等维度做出选择
3. 优化实践:分析你现有RAG系统的检索延迟和召回率,针对性地调整索引参数和分块策略
4. 知识沉淀:将向量数据库相关的技术选型、踩坑记录、优化经验沉淀到团队知识库中
下期预告:Day13我们将进入《企业知识库搭建实战》。我们会把今天学习的向量数据库知识应用到真实场景中,从需求分析、架构设计、数据处理、到系统部署,完整构建一个企业级RAG知识库系统。届时会涉及PDF解析、表格处理、多语言支持等实战技巧,敬请期待。
如果你在实践过程中遇到任何问题,欢迎在评论区留言,我会尽力为你解答。