【进阶实战】Day13:企业知识库搭建实战

当RAG技术从实验室走向生产线,企业知识库成为最能体现其价值的应用场景。一套设计良好的企业知识库系统,能够将散落在各个角落的文档、表格、邮件、会议记录等海量信息转化为可检索、可理解的智能知识中枢,让员工在几秒钟内找到过去需要翻阅数小时才能找到的答案。
今天,我们将通过一个完整的实战项目,从需求分析、架构设计、数据处理、到系统部署,手把手教你在三天内搭建一套生产级别的企业知识库系统。
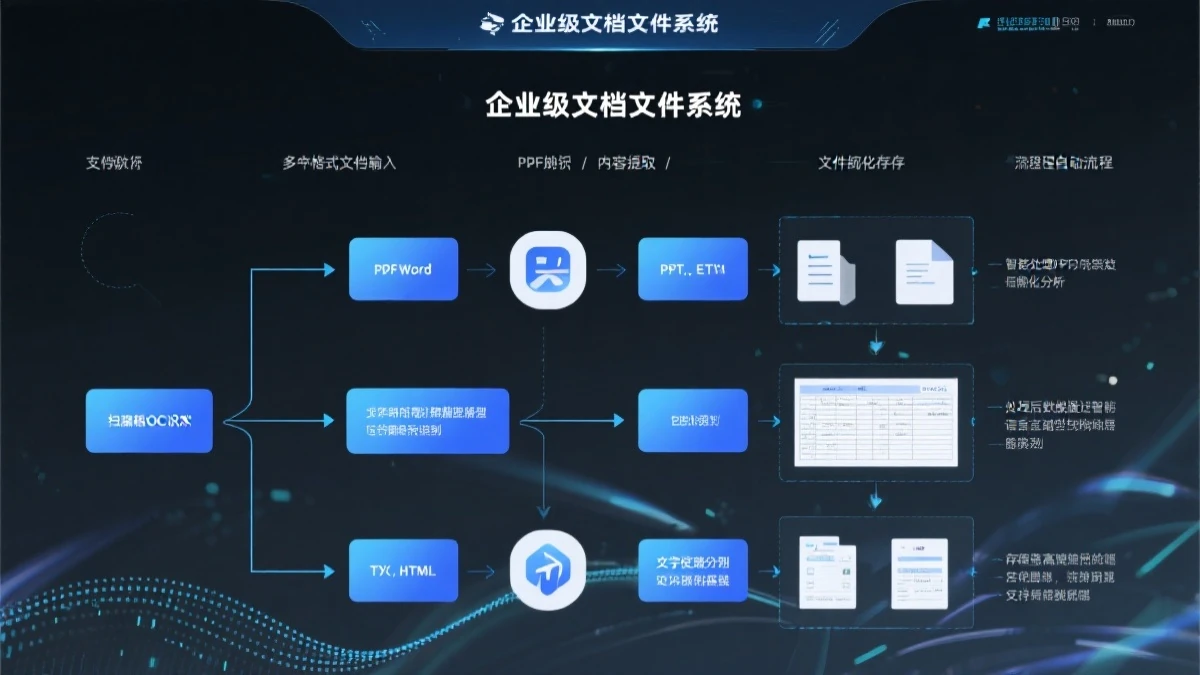
企业文档处理全流程:从多格式文档到智能检索
一、真实场景的需求分析
在动手之前,我们先来梳理一下企业知识库的典型需求。很多团队一开始热情满满地搭建系统,上线后却发现”没人用”——原因往往是在设计阶段就没有真正理解业务场景。
1.1 知识库的核心使用场景
场景一:新员工入职培训。 新人入职第一天有大量问题:公司的报销流程是什么?请假制度如何?技术文档在哪里?传统的做法是分配一个”导师”从头带起,但这种方式效率低下且质量参差不齐。如果有一套完善的知识库,新人可以自主搜索快速找到答案,HR也能将培训内容系统化、标准化。
场景二:客服团队的知识支撑。 客服每天面对大量重复性问题:”你们的退换货政策是什么?”、”如何重置账户密码?”、”产品坏了怎么维修?”如果每次都要人工查找手册,不仅效率低,而且回复标准不一。知识库可以让AI先理解问题,自动检索最相关的答案,确保回复既快又准。
场景三:技术团队的故障排查。 当系统出现故障时,工程师通常需要查阅大量历史文档、运维手册、代码注释来定位问题。如果有一套智能知识库,只需描述问题现象,系统就能快速定位相关的故障记录和解决方案,大幅缩短MTTR(平均恢复时间)。
场景四:销售团队的产品话术支持。 销售在跟客户沟通时,经常需要快速查找产品规格、成功案例、竞品对比等信息。如果知识库能根据客户的问题自动推荐最合适的话术和资料,销售效率和产品认知都会大幅提升。
1.2 知识类型的全面梳理
企业知识库需要处理的知识类型远比想象中丰富:
结构化文档:PDF、Word、PPT等格式的正式文档,如管理制度、产品手册、培训教材。这类文档通常有明确的结构,但直接用OCR识别效果往往不佳,需要专门的解析方案。
表格数据:Excel表格、项目管理文档中的数据表格。表格数据的处理难点在于如何理解行列关系和单元格语义。
网页内容:企业官网、Confluence、Wikis等在线文档系统。网页内容通常需要先爬取再处理。
即时通讯记录:钉钉、企业微信、飞书等IM工具中的讨论记录。这些对话中往往包含大量的”隐性知识”——解决问题的方法、对需求的讨论、对技术的理解等。
邮件内容:商务邮件、项目沟通邮件中包含大量有价值的信息,但通常分散在邮件系统中。
代码与注释:代码本身的注释、README文档、API文档等。这些是技术团队最核心的知识资产。
1.3 常见失败原因与避坑指南
根据大量企业知识库项目的经验,以下是导致项目失败的最常见原因:
失败原因一:一次性想做太多。 很多团队一开始就想要一个”什么都能搜”的系统,结果由于数据源太多、处理难度太大,项目周期无限延长,最终不了了之。正确的做法是”小步快跑”——先从一个高频场景、一类核心数据开始,逐步扩展。
失败原因二:只管建不管用。 知识库上线后缺乏运营,用户贡献知识的激励机制缺失,数据库逐渐变得陈旧过时。解决方案是从一开始就把”知识运营”纳入设计,建立知识贡献积分、知识质量评分等机制。
失败原因三:搜索效果差却不优化。 很多知识库上线后搜索效果不理想,但团队不知道如何优化。其实向量检索效果的提升有系统化的方法:从评估指标开始、逐层分析问题、针对性优化。
失败原因四:忽略数据安全。 知识库中往往包含敏感信息,如果权限设计不当,可能导致机密外泄。必须在设计阶段就把访问控制、敏感词过滤、审计日志等功能纳入架构。
二、系统架构设计
好的架构是成功的一半。在开始编码之前,我们需要花足够的时间设计系统架构。
2.1 整体架构概览
一个完整的企业知识库RAG系统通常包含以下组件:
数据接入层:负责从各类数据源(文件系统、S3、数据库、API等)采集原始文档。需要支持定时同步增量数据,以及手动触发的全量同步。
文档解析层:将PDF、Word、PPT等非结构化文档解析为可处理的文本块。这一层是整个系统中技术难度最高的部分,需要处理表格、图表、多列布局等复杂元素。
向量化处理层:调用嵌入模型将文本块转换为向量表示,并存储到向量数据库中。同时需要管理向量的元数据(如文档来源、时间、权限级别等)。
检索推理层:接收用户查询,调用向量数据库进行语义检索,对结果进行重排序,最后组装上下文调用大语言模型生成答案。
应用交互层:面向终端用户的界面,包括网页端、移动端、钉钉/飞书插件等多种形式。
2.2 数据处理流水线设计
数据处理是知识库系统的核心。一个设计良好的数据处理流水线需要考虑以下要素:
文档解析策略:不同类型的文档需要不同的解析策略。PDF需要使用专门的解析库(如PyMuPDF、pdfplumber);Word文档可以使用python-docx直接读取;PPT则需要python-pptx。关键是要保留文档结构信息(标题层级、列表、表格),这些信息对于后续的文本分块至关重要。
智能分块算法:分块策略直接影响检索效果。我们推荐使用”层次化分块”策略:先按语义段落粗分,再根据段落长度决定是否进一步切分。切分时要避免把一个完整的句子从中间截断,也要保持每个块有足够的上下文信息。
元数据提取:每个文本块都应该携带丰富的元数据:文档标题、来源系统、创建时间、作者、权限级别、业务分类等。这些元数据不仅用于检索过滤,还能在答案中展示来源,增强用户信任。
增量更新机制:企业知识库的数据是持续更新的。系统需要支持增量同步——只处理新增和修改的文档,而不是每次都全量处理。可以通过记录文档哈希值或最后修改时间来判断是否需要重新处理。
2.3 向量数据库选型建议
在《Day12:向量数据库》的基础上,企业知识库场景下我们需要更认真地考虑选型:
如果数据规模在千万级以下,Milvus是最稳妥的选择。它开源可控、社区活跃、文档完善,能够满足大部分企业知识库的需求。对于敏感数据,可以私有化部署,数据完全不离开企业网络。
如果团队规模小、希望快速上线,Pinecone或Zilliz Cloud(Milvus的云服务)是不错的选择。托管服务让你不需要关心运维,但需要评估数据安全合规要求。
如果需要同时处理结构化数据和向量(如同时搜索”2024年3月的财务报表”和语义相关的分析报告),Weaviate的知识图谱能力会派上用场。
2.4 权限与安全设计
企业知识库必须考虑权限控制。以下是几个关键设计:
文档级别的权限:不同用户看到不同的知识库内容。如财务文档只有财务部门可见,销售数据只有销售团队可查。
检索时的权限过滤:向量检索前先根据用户权限筛选可检索的文档范围,确保用户不会搜到无权访问的内容。
敏感词过滤:在答案生成前,对检索结果和生成内容进行敏感词扫描,避免泄露机密信息。
操作审计日志:记录所有检索和访问行为,便于安全审计和问题追溯。
三、实战:PDF文档处理全流程
PDF是企业知识库中最常见的数据格式,但其解析难度也是最高的。接下来的内容将详细介绍如何处理各类PDF文档。
3.1 基础文本PDF处理
对于以文本为主的PDF(如Word导出的PDF、技术文档等),处理流程相对简单:
import fitz # PyMuPDF
from langchain.text_splitter import RecursiveCharacterTextSplitter
def extract_text_from_pdf(pdf_path: str) -> list[str]:
"""从PDF提取文本并分块"""
doc = fitz.open(pdf_path)
full_text = []
for page_num, page in enumerate(doc):
text = page.get_text("text")
if text.strip():
full_text.append({
"page_num": page_num + 1,
"text": text.strip(),
"source": pdf_path
})
doc.close()
return full_text
def chunk_texts(texts: list[dict], chunk_size: int = 500, overlap: int = 50) -> list[dict]:
"""将文本分块"""
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=overlap,
separators=["\n\n", "\n", "。", "!", "?", ",", " ", ""]
)
chunks = []
for item in texts:
new_chunks = text_splitter.split_text(item["text"])
for chunk in new_chunks:
chunks.append({
"content": chunk,
"page_num": item["page_num"],
"source": item["source"]
})
return chunks3.2 表格密集型PDF处理
财务报告、统计报表等PDF的核心信息往往以表格形式呈现。普通的文本提取会把表格弄得支离破碎,我们需要专门的表格提取方案:
import pdfplumber
def extract_tables_from_pdf(pdf_path: str, page_numbers: list[int] = None):
"""从指定页面提取表格"""
tables_data = []
with pdfplumber.open(pdf_path) as pdf:
pages = pdf.pages if not page_numbers else [pdf.pages[i-1] for i in page_numbers]
for page in pages:
# 提取表格
extracted_tables = page.extract_tables()
for table in extracted_tables:
if table and len(table) > 1: # 至少要有表头和一行数据
# 将表格转换为markdown格式,便于后续处理
markdown_table = table_to_markdown(table)
tables_data.append({
"page": page.page_number,
"table": markdown_table,
"source": pdf_path
})
return tables_data
def table_to_markdown(table: list[list[str]]) -> str:
"""将表格列表转换为Markdown格式"""
if not table:
return ""
# 表头
header = table[0]
markdown = "| " + " | ".join(str(cell) if cell else "" for cell in header) + " |\n"
markdown += "| " + " | ".join(["---"] * len(header)) + " |\n"
# 数据行
for row in table[1:]:
markdown += "| " + " | ".join(str(cell) if cell else "" for cell in row) + " |\n"
return markdown3.3 扫描件PDF处理
扫描件PDF本质上是一张张图片,需要通过OCR(光学字符识别)来提取文字。Tesseract是开源社区最流行的OCR引擎:
import pytesseract
from PIL import Image
import fitz
def extract_text_from_scanned_pdf(pdf_path: str, lang: str = "chi_sim+eng") -> list[dict]:
"""从扫描件PDF提取文本"""
doc = fitz.open(pdf_path)
results = []
for page_num, page in enumerate(doc):
# 将页面转换为图片
mat = fitz.Matrix(2, 2) # 2倍放大,提高OCR准确率
pix = page.get_pixmap(matrix=mat)
img_data = pix.tobytes("png")
# 使用PIL处理图片
image = Image.open(io.BytesIO(img_data))
# OCR识别
text = pytesseract.image_to_string(image, lang=lang)
if text.strip():
results.append({
"page_num": page_num + 1,
"text": text.strip(),
"source": pdf_path
})
doc.close()
return results3.4 多列排版PDF处理
学术论文、行业报告等PDF通常采用多列排版,简单的文本提取会打乱阅读顺序。需要先分析页面布局,再按正确的顺序提取文字:
def extract_text_from_multicolumn_pdf(pdf_path: str) -> list[dict]:
"""处理多列排版PDF"""
doc = fitz.open(pdf_path)
results = []
for page_num, page in enumerate(doc):
# 获取页面的文本块(blocks)
blocks = page.get_text("blocks")
# 按阅读顺序排序(从上到下、从左到右)
sorted_blocks = sorted(blocks, key=lambda b: (b[1], b[0])) # y1, x1
full_text = ""
for block in sorted_blocks:
# 跳过图片块(block[6] == 1 表示是图片)
if block[6] == 1:
continue
block_text = block[4].strip()
if block_text:
full_text += block_text + "\n"
if full_text.strip():
results.append({
"page_num": page_num + 1,
"text": full_text.strip(),
"source": pdf_path
})
doc.close()
return results四、实战:企业知识库完整搭建
理论讲完了,接下来进入实战环节。我们将搭建一个完整的知识库系统,处理包含文档、表格、代码等多种格式的企业知识。
4.1 项目初始化与依赖安装
# 创建项目目录
mkdir enterprise-knowledge-base
cd enterprise-knowledge-base
# 创建虚拟环境
python -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
# 安装核心依赖
pip install pymilvus milvus documents langchain langchain-community
pip install python-docx pdfplumber pytesseract pymupdf
pip install sentence-transformers transformers torch
pip install gradio # Web界面4.2 配置管理模块
from pathlib import Path
from typing import Optional
import yaml
class Config:
"""知识库配置管理"""
def __init__(self, config_path: str = "config.yaml"):
self.config_path = Path(config_path)
self._load_config()
def _load_config(self):
if self.config_path.exists():
with open(self.config_path) as f:
self.config = yaml.safe_load(f)
else:
self.config = self._default_config()
def _default_config(self) -> dict:
return {
"milvus": {
"host": "localhost",
"port": 19530,
"collection_name": "enterprise_knowledge"
},
"embeddings": {
"model_name": "BAAI/bge-large-zh-v1.5",
"dimension": 1024
},
"chunks": {
"chunk_size": 500,
"chunk_overlap": 50
},
"retrieval": {
"top_k": 5,
"score_threshold": 0.5
}
}
def save(self):
with open(self.config_path, 'w') as f:
yaml.dump(self.config, f)
# 初始化配置
config = Config()4.3 文档处理器实现
from abc import ABC, abstractmethod
from pathlib import Path
from typing import List, Dict, Any
import io
class DocumentProcessor(ABC):
"""文档处理器基类"""
@abstractmethod
def process(self, file_path: str) -> List[Dict[str, Any]]:
"""处理文档并返回文本块列表"""
pass
class PDFProcessor(DocumentProcessor):
"""PDF文档处理器"""
def __init__(self, chunk_size: int = 500, chunk_overlap: int = 50):
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separators=["\n\n", "\n", "。", "!", "?", ",", " ", ""]
)
def process(self, file_path: str) -> List[Dict[str, Any]]:
import fitz
chunks = []
doc = fitz.open(file_path)
for page_num, page in enumerate(doc):
text = page.get_text("text")
if text.strip():
page_chunks = self.text_splitter.split_text(text.strip())
for chunk in page_chunks:
chunks.append({
"content": chunk,
"metadata": {
"source": str(file_path),
"page": page_num + 1,
"type": "pdf"
}
})
doc.close()
return chunks
class WordProcessor(DocumentProcessor):
"""Word文档处理器"""
def process(self, file_path: str) -> List[Dict[str, Any]]:
from docx import Document as DocxDocument
chunks = []
doc = DocxDocument(file_path)
full_text = []
for para in doc.paragraphs:
if para.text.strip():
full_text.append(para.text.strip())
text = "\n".join(full_text)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separators=["\n\n", "\n", "。", "!", "?", ",", " ", ""]
)
text_chunks = text_splitter.split_text(text)
for chunk in text_chunks:
chunks.append({
"content": chunk,
"metadata": {
"source": str(file_path),
"type": "docx"
}
})
return chunks
class DocumentPipeline:
"""文档处理流水线"""
def __init__(self):
self.processors = {
".pdf": PDFProcessor(),
".docx": WordProcessor(),
".doc": WordProcessor(),
".txt": TextProcessor()
}
def process_file(self, file_path: str) -> List[Dict[str, Any]]:
ext = Path(file_path).suffix.lower()
processor = self.processors.get(ext)
if not processor:
print(f"Unsupported file type: {ext}")
return []
return processor.process(file_path)
def process_directory(self, dir_path: str, recursive: bool = True) -> List[Dict[str, Any]]:
"""处理目录下的所有支持的文件"""
all_chunks = []
path = Path(dir_path)
pattern = "**/*" if recursive else "*"
for file_path in path.glob(pattern):
if file_path.is_file():
ext = file_path.suffix.lower()
if ext in self.processors:
print(f"Processing: {file_path}")
chunks = self.process_file(str(file_path))
all_chunks.extend(chunks)
return all_chunks4.4 向量数据库操作模块
from pymilvus import MilvusClient, DataType
from typing import List, Dict, Any
import numpy as np
class KnowledgeBase:
"""Milvus知识库操作类"""
def __init__(self, host: str = "localhost", port: int = 19530, collection_name: str = "enterprise_knowledge"):
self.client = MilvusClient(uri=f"http://{host}:{port}")
self.collection_name = collection_name
self.dimension = 1024 # BGE-large的维度
def create_collection(self):
"""创建Collection"""
if self.client.has_collection(self.collection_name):
self.client.drop_collection(self.collection_name)
schema = MilvusClient.create_schema(
auto_id=True,
enable_dynamic_field=True,
)
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name="content", datatype=DataType.VARCHAR, max_length=65535)
schema.add_field(field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=self.dimension)
schema.add_field(field_name="source", datatype=DataType.VARCHAR, max_length=512)
schema.add_field(field_name="page", datatype=DataType.INT64)
schema.add_field(field_name="doc_type", datatype=DataType.VARCHAR, max_length=64)
self.client.create_collection(
collection_name=self.collection_name,
schema=schema
)
# 创建索引
index_params = self.client.prepare_index_params()
index_params.add_index(
field_name="vector",
index_type="HNSW",
metric_type="COSINE",
params={"M": 16, "efConstruction": 200}
)
self.client.create_index(
collection_name=self.collection_name,
index_params=index_params
)
self.client.load(self.collection_name)
print(f"Collection '{self.collection_name}' created successfully!")
def insert_chunks(self, chunks: List[Dict[str, Any]], embeddings: list):
"""批量插入文档块"""
data = []
for chunk, embedding in zip(chunks, embeddings):
data.append({
"content": chunk["content"],
"vector": embedding,
"source": chunk["metadata"].get("source", ""),
"page": chunk["metadata"].get("page", 0),
"doc_type": chunk["metadata"].get("type", "unknown")
})
result = self.client.insert(
collection_name=self.collection_name,
data=data
)
print(f"Inserted {len(chunks)} chunks")
return result
def search(self, query_vector: list, top_k: int = 5, filters: dict = None) -> List[Dict[str, Any]]:
"""向量检索"""
search_params = {
"metric_type": "COSINE",
"params": {"ef": 128}
}
expr = None
if filters:
conditions = []
if "source" in filters:
conditions.append(f'source == "{filters["source"]}"')
if "doc_type" in filters:
conditions.append(f'doc_type == "{filters["doc_type"]}"')
if conditions:
expr = " and ".join(conditions)
results = self.client.search(
collection_name=self.collection_name,
data=[query_vector],
limit=top_k,
search_params=search_params,
output_fields=["content", "source", "page", "doc_type"],
expr=expr
)
return [
{
"content": r["entity"]["content"],
"source": r["entity"]["source"],
"page": r["entity"]["page"],
"doc_type": r["entity"]["doc_type"],
"score": r["distance"]
}
for r in results[0]
]4.5 Web界面实现
import gradio as gr
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
# 初始化嵌入模型
embeddings = HuggingFaceBgeEmbeddings(
model_name="BAAI/bge-large-zh-v1.5",
model_kwargs={"device": "cuda"},
encode_kwargs={"normalize_embeddings": True}
)
# 初始化知识库
kb = KnowledgeBase(host="localhost", port=19530)
def search_knowledge_base(query: str, top_k: int = 5):
"""搜索知识库"""
# 将问题转换为向量
query_vector = embeddings.embed_query(query)
# 检索相关文档
results = kb.search(query_vector, top_k=top_k)
if not results:
return "未找到相关内容,请尝试其他关键词。"
# 组装回答
response = f"找到 {len(results)} 条相关内容:\n\n"
for i, result in enumerate(results, 1):
response += f"**{i}. {result['source']} (页码: {result['page']})**\n"
response += f"相关度: {result['score']:.4f}\n"
response += f"内容摘要: {result['content'][:200]}...\n\n"
return response
# 创建Gradio界面
with gr.Blocks(title="企业知识库助手") as demo:
gr.Markdown("# 🔍 企业知识库智能助手")
gr.Markdown("基于RAG技术的企业知识库问答系统")
with gr.Row():
with gr.Column():
query_input = gr.Textbox(
label="请输入您的问题",
placeholder="例如:公司报销流程是什么?",
lines=3
)
top_k_slider = gr.Slider(
minimum=1,
maximum=10,
value=5,
step=1,
label="返回结果数量"
)
search_btn = gr.Button("🔍 搜索", variant="primary")
with gr.Column():
output = gr.Textbox(
label="搜索结果",
lines=15
)
search_btn.click(
fn=search_knowledge_base,
inputs=[query_input, top_k_slider],
outputs=output
)
# 启动服务
demo.launch(
server_name="0.0.0.0",
server_port=7860,
share=False
)
Docker Compose一键部署:Milvus与服务编排
五、系统部署与运维
代码开发完成后,如何把它部署到生产环境并稳定运行?这一部分将介绍企业知识库的部署方案和运维要点。
5.1 Docker Compose一键部署
对于中小规模团队,推荐使用Docker Compose快速部署:
version: '3.8'
services:
milvus-etcd:
image: quay.io/coreos/etcd:v3.5.5
environment:
- ETCD_AUTO_COMPACTION_MODE=revision
- ETCD_AUTO_COMPACTION_RETENTION=1000
- ETCD_QUOTA_BACKEND_BYTES=4294967296
volumes:
- ./etcd:/etcd
command: etcd -advertise-client-urls=http://127.0.0.1:2379 -listen-client-urls http://0.0.0.0:2379 --data-dir /etcd
milvus-minio:
image: minio/minio:RELEASE.2023-03-20T20-16-18Z
environment:
MINIO_ACCESS_KEY: minioadmin
MINIO_SECRET_KEY: minioadmin
volumes:
- ./minio:/minio_data
command: minio server /minio_data --console-address ":9001"
milvus:
image: milvusdb/milvus:v3.0.0
ports:
- "19530:19530"
- "9091:9091"
environment:
ETCD_ENDPOINTS: milvus-etcd:2372
MINIO_ADDRESS: milvus-minio:9000
volumes:
- ./milvus_data:/var/lib/milvus
depends_on:
- milvus-etcd
- milvus-minio
knowledge-base:
build: .
ports:
- "7860:7860"
environment:
MILVUS_HOST: milvus
MILVUS_PORT: 19530
depends_on:
- milvus5.2 增量更新与定时同步
知识库需要持续更新,以下是一个增量同步的示例:
import hashlib
from datetime import datetime
import schedule
def compute_file_hash(file_path: str) -> str:
"""计算文件哈希"""
with open(file_path, 'rb') as f:
return hashlib.md5(f.read()).hexdigest()
def sync_knowledge_base():
"""增量同步知识库"""
processed_hashes = load_processed_hashes() # 从数据库加载已处理文件哈希
kb_directory = Path("knowledge_base")
new_files = []
for file_path in kb_directory.glob("**/*"):
if file_path.is_file() and file_path.suffix.lower() in ['.pdf', '.docx', '.doc']:
file_hash = compute_file_hash(str(file_path))
if file_hash not in processed_hashes:
new_files.append((str(file_path), file_hash))
processed_hashes.add(file_hash)
if new_files:
print(f"发现 {len(new_files)} 个新文件需要处理")
process_and_index_files(new_files)
save_processed_hashes(processed_hashes)
else:
print("没有新文件需要处理")
# 定时任务:每天早上9点执行
schedule.every().day.at("09:00").do(sync_knowledge_base)
while True:
schedule.run_pending()
time.sleep(60)5.3 监控与告警
生产环境必须配备监控体系。以下是建议的监控指标:
系统层面:
- Milvus服务CPU/内存使用率
- 磁盘空间使用率
- 网络吞吐量
业务层面:
- 每日检索量、检索响应时间
- 检索结果为空的比例
- Token消耗量
告警规则:
- 响应时间超过5秒
- 检索结果为空率超过20%
- 磁盘空间使用率超过80%
六、效果评估与持续优化
知识库上线后,评估效果并持续优化是长期工作。
6.1 检索效果评估指标
召回率(Recall):相关文档被检索出来的比例。计算方法:检索结果中相关文档数 / 总相关文档数。
精确率(Precision):检索结果中相关文档的比例。计算方法:检索结果中相关文档数 / 检索结果总数。
MRR(Mean Reciprocal Rank):相关文档平均排名的倒数。MRR越高,说明正确答案的排名越靠前。
NDCG(Normalized Discounted Cumulative Gain):综合考虑相关度和排名的评估指标,是最全面的检索效果指标之一。
6.2 用户反馈收集
用户的即时反馈是最好的优化信号:
def log_user_feedback(query: str, results: list, selected_idx: int, rating: int):
"""记录用户反馈"""
feedback = {
"query": query,
"timestamp": datetime.now().isoformat(),
"returned_results": [r["content"][:100] for r in results],
"selected_index": selected_idx,
"rating": rating # 1-5分
}
# 保存到反馈数据库
save_feedback(feedback)
# 分析负面反馈
if rating < 3:
analyze_poor_result(query, results[selected_idx])6.3 针对性优化策略
根据评估结果,采取针对性的优化措施:
问题一:相关文档未被召回。
- 降低相似度阈值
- 尝试不同的嵌入模型
- 调整分块策略,减小块大小
问题二:检索结果排名不理想。
- 引入Rerank模型对初筛结果重排
- 调优HNSW的ef参数
- 考虑引入关键词匹配作为排序特征
问题三:特定类型查询效果差。
- 针对该类型Query收集更多训练数据
- 调整Prompt引导检索方向
- 优化该类型文档的处理流程
七、总结与行动建议
今天的实战教程我们完整走完了企业知识库从需求分析、架构设计、数据处理、系统实现、到部署运维的全流程。
核心要点回顾:
需求层面:从真实场景出发,小步快跑,不要一开始就追求”大而全”。新员工培训、客服支持、技术故障排查是最适合RAG知识库的三个场景。
架构层面:采用分层设计,数据接入、文档解析、向量化、检索推理、应用交互各层职责清晰。权限控制要从设计阶段就纳入考量。
数据处理层面:PDF处理是技术难点,文本型PDF、表格密集型PDF、扫描件PDF、多列排版PDF需要不同的处理策略。分块策略直接影响检索效果,建议使用层次化分块。
运维层面:增量同步机制保证知识库持续更新,监控告警体系确保系统健康运行,用户反馈闭环推动持续优化。
今日行动建议:
1. 梳理数据资产:列出你团队内部最重要的3类文档,作为知识库的第一批数据
2. 选定试点场景:从新员工培训或客服支持中选择一个作为切入点
3. 完成环境搭建:按照今天的内容,完成Milvus环境部署和基础代码配置
4. 处理第一批数据:尝试处理3-5份真实的内部文档,验证处理流程
下期预告:Day14我们将深入探讨《Rerank与重排技术》。当向量检索返回的候选集不够精准时,Rerank模型能够通过更深入的理解找出真正相关的内容。我们将详细介绍Rerank的原理、主流模型对比、以及在RAG系统中的集成方法。敬请期待!