【进阶实战】Day14:Rerank与重排技术——让RAG结果精准度翻倍
在RAG系统的实际应用中,你可能遇到过这样的困惑:明明向量检索已经找到了”看起来相关”的文档,但大模型生成的回答却答非所问。这不是模型的问题,而是向量检索的”粗筛”机制天然存在精度天花板。
打个比方:向量检索就像是用大网眼渔网快速捞鱼——能捞到目标鱼群附近的所有鱼类,但精确挑出你想要的那几条,还需要人工复筛。Rerank(重排序)技术就是这位”人工复筛”的角色,它通过更精细的理解判断,将最相关的内容排在最前面。
今天这篇文章,我们将深入剖析Rerank技术的底层原理、主流模型对比、以及在RAG系统中的集成方法。
一、为什么需要Rerank
1.1 向量检索的精度困境
向量检索采用近似最近邻(ANN)算法,其核心目标是在可接受的时间成本内找到”差不多相关”的结果,而非逐一比较所有文档找出”绝对最相关”的结果。
这种设计在数据规模达到百万、千万级别时是必要的——暴力计算所有向量的距离需要O(N)的时间复杂度,而HNSW等ANN算法将这个时间降低到O(log N)。代价是检索结果存在一定的不确定性,尤其是在相关文档和非相关文档的向量表示比较接近时。
举例来说,用户问:”如何申请年假?”向量检索可能返回以下内容:
1. “年假申请流程及注意事项”(相关)
2. “公司年假制度说明”(相关)
3. “请假管理规定”(部分相关,但讲的是所有假期)
4. “病假申请流程”(不太相关,但包含”申请”和”假”)
5. “加班调休政策”(不相关)
向量相似度排名第4、5位的内容,语义上与用户问题有表面相似性,但实际并非用户想要的答案。
1.2 Rerank的降维打击
Rerank模型通常采用基于Transformer的交叉编码器架构,它能够同时处理”问题”和”候选文档”,计算它们之间的深度语义关联度。这个过程比向量检索的简单距离计算要”重”得多——交叉编码器需要将问题和文档一起通过完整的Transformer层,而非分别处理后计算距离。
但正因为”重”,Rerank模型能够捕捉到向量检索无法捕捉的精细语义差异。例如:
- 问题:”如何申请年假”
- 文档A:”员工请年假需提前3天通过OA系统提交申请”
- 文档B:”因病需要请假时,需提供医院证明”
交叉编码器会理解”年假”和”病假”的本质区别,给文档A打高分,文档B打低分。而向量检索可能只看到了”申请”这个共同词汇。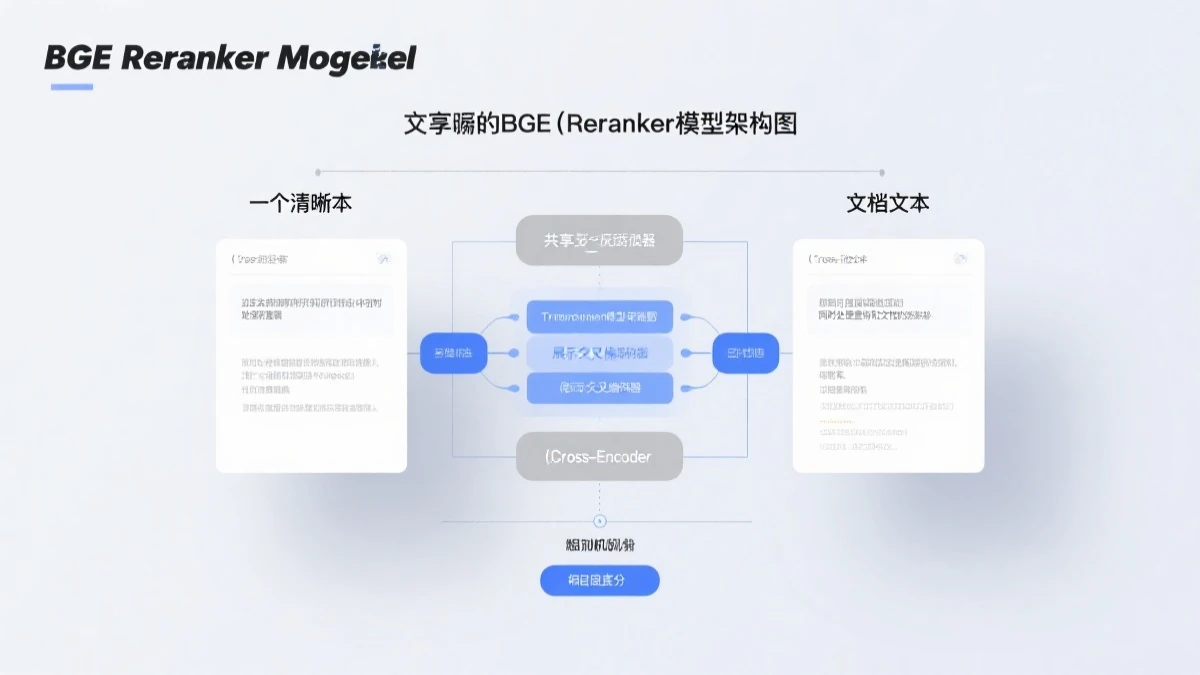
1.3 二阶段检索的经典范式
向量检索 + Rerank的二阶段架构已成为RAG系统的标准范式:
第一阶段:向量检索(Recall-Oriented)
- 目标:召回尽可能多的潜在相关文档
- 策略:使用较粗的向量索引,快速返回Top 50~100的候选
- 要求:速度快、能覆盖大多数相关文档
第二阶段:Rerank(Precision-Oriented)
- 目标:从候选中筛选出最相关的内容
- 策略:使用精确的交叉编码器,对Top-K重新排序
- 要求:精度高、能区分细微语义差异
这种”先广撒网、再精挑选”的策略,兼顾了检索的覆盖率和精准度。
二、Rerank模型深度对比
当前主流的Rerank模型主要分为两类:开源部署方案和API调用方案。
2.1 开源Rerank模型
BGE-Reranker(BAAI出品)
- 参数量:约2.7亿参数
- 支持语言:多语言(中文优化)
- 部署方式:本地推理,支持GPU加速
- 特点:国产之光,中文场景表现优异,与BGE嵌入模型同源,配套使用效果最好
- 推荐配置:Rerank-Top-K设置为20~50,配合向量检索Top-100使用
BCE-Reranker(网梯科技出品)
- 参数量:约1.1亿参数
- 支持语言:中文为主
- 部署方式:本地推理
- 特点:轻量级,中文场景效果稳定
Cohere Rerank
- 虽然Cohere提供API版本,但其底层模型也可以本地部署
- 特点:英文场景表现极佳,多语言支持一般
2.2 API调用方案
Cohere Rerank API
- 使用方式:API调用,按量计费
- 价格:相对昂贵,适合调用量不大的场景
- 优点:无需运维,模型持续更新
- 缺点:数据需要发送给第三方,存在隐私顾虑
OpenAI Rerank API
- OpenAI官方并未提供专门的Rerank服务
- 可以使用GPT模型通过Prompt Engineering实现类似效果
- 缺点:成本高、速度慢,不适合高频调用
2.3 模型选型建议
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 中文企业知识库 | BGE-Reranker | 中文优化、免费、本地部署 |
| 英文为主 | Cohere Rerank API | 英文效果最佳 |
| 数据隐私敏感 | BGE-Reranker本地部署 | 数据不出本地 |
| 快速验证 | Cohere Rerank API | 无需配置环境 |
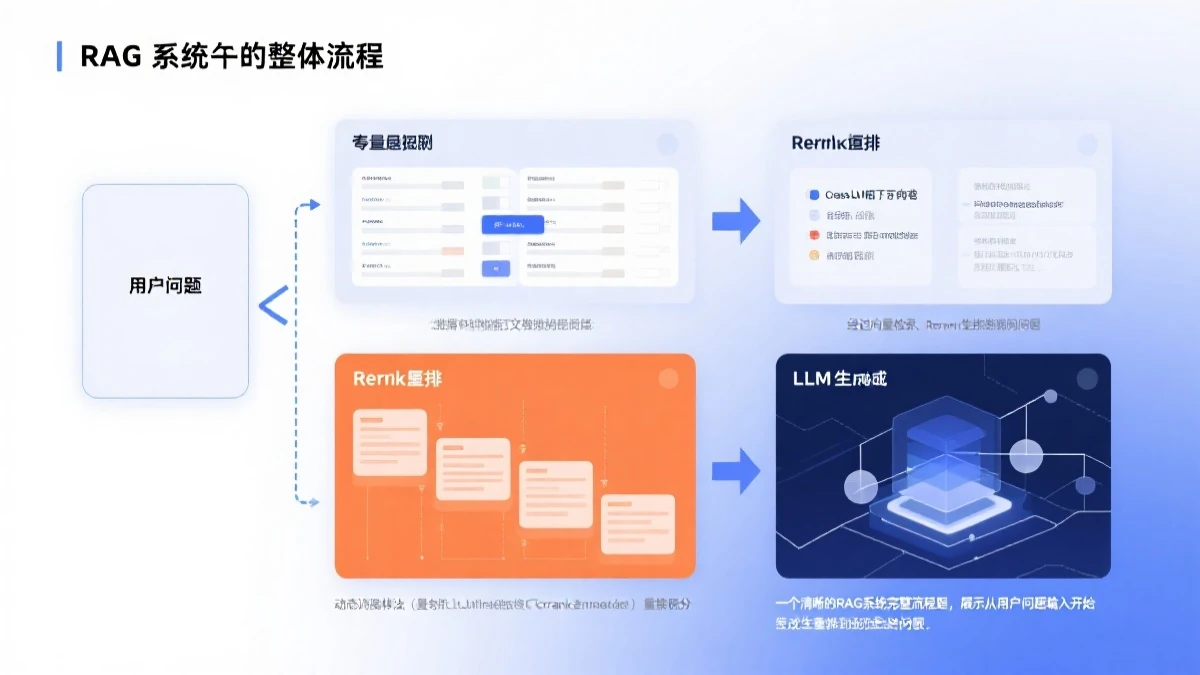
三、Rerank实战集成
3.1 环境准备与模型下载
# 安装必要依赖
# pip install sentence-transformers torch
from sentence_transformers import CrossEncoder
# 加载BGE Reranker模型
model = CrossEncoder('BAAI/bge-reranker-large', max_length=512)3.2 基础Rerank实现
def rerank_documents(query: str, documents: list[str], top_k: int = 5) -> list[dict]:
"""
对文档列表进行重排序
Args:
query: 用户问题
documents: 文档列表(通常是向量检索返回的候选)
top_k: 返回的最相关文档数量
Returns:
重排序后的文档列表,按相关度从高到低排列
"""
# 构建query-document pair
pairs = [(query, doc) for doc in documents]
# 批量预测相关度分数
scores = model.predict(pairs)
# 按分数排序
doc_scores = list(zip(documents, scores))
doc_scores.sort(key=lambda x: x[1], reverse=True)
# 返回Top-K结果
return [
{"content": doc, "score": float(score)}
for doc, score in doc_scores[:top_k]
]
# 使用示例
query = "如何申请年假?"
documents = [
"员工请年假需提前3天通过OA系统提交申请,审批通过后即可休假。",
"公司年假制度:工作满1年享5天年假,满5年享10天年假。",
"请假管理规定:所有请假需提前申请,紧急情况可事后补假。",
"因病需要请假时,需提供医院证明。",
"加班调休政策:加班可在6个月内申请调休。"
]
results = rerank_documents(query, documents, top_k=3)
for i, r in enumerate(results, 1):
print(f"{i}. [分数: {r['score']:.4f}] {r['content'][:50]}...")3.3 RAG流水线集成
将Rerank集成到完整的RAG流水线:
from milvus import Milvus
from sentence_transformers import CrossEncoder
class RAGRerankPipeline:
"""带Rerank的RAG检索流水线"""
def __init__(self, milvus_client, embed_model, rerank_model):
self.milvus = milvus_client
self.embed_model = embed_model
self.rerank_model = rerank_model
def retrieve(self, query: str, top_k_vector: int = 100, top_k_rerank: int = 5):
"""
两阶段检索:
1. 向量检索:快速召回Top-K候选
2. Rerank:精确排序
"""
# 阶段1:向量检索
query_vector = self.embed_model.embed_query(query)
vector_results = self.milvus.search(
collection_name="knowledge_base",
data=[query_vector],
limit=top_k_vector,
output_fields=["content", "source"]
)
# 提取文档内容
candidate_docs = [r["entity"]["content"] for r in vector_results[0]]
if not candidate_docs:
return []
# 阶段2:Rerank重排
reranked = self.rerank_documents(query, candidate_docs, top_k_rerank)
return reranked
def rerank_documents(self, query: str, documents: list[str], top_k: int = 5):
"""使用Rerank模型重排"""
pairs = [(query, doc) for doc in documents]
scores = self.rerank_model.predict(pairs)
doc_scores = list(zip(documents, scores))
doc_scores.sort(key=lambda x: x[1], reverse=True)
return [
{"content": doc, "score": float(score)}
for doc, score in doc_scores[:top_k]
]
def answer(self, query: str, top_k: int = 5):
"""完整RAG流程:检索 → Rerank → 生成"""
# 检索
results = self.retrieve(query, top_k_vector=100, top_k_rerank=top_k)
if not results:
return "抱歉,未找到相关信息。"
# 组装上下文
context = "\n\n".join([
f"【文档{i+1}】{r['content']}"
for i, r in enumerate(results)
])
# 调用LLM生成
prompt = f"""基于以下参考资料回答问题。如参考材料不包含答案,请如实说明。
参考资料:
{context}
问题:{query}
回答:"""
# 实际使用时调用LLM API
response = call_llm(prompt)
return response四、Rerank进阶技巧
4.1 分层Rerank策略
对于超大规模候选集,可以采用分层Rerank策略:
def layered_rerank(query: str, documents: list[str], stages: list[int] = [50, 20, 5]):
"""
分层Rerank:逐步缩小候选范围,提高效率
Args:
documents: 初始候选列表
stages: 每轮的候选数量,如[50, 20, 5]表示第一轮50个,第二轮20个,最终返回5个
"""
current_docs = documents
for i, stage_size in enumerate(stages[:-1]):
# 每轮筛选stage_size个,进入下一轮
pairs = [(query, doc) for doc in current_docs[:stage_size * 3]] # 多取一些
scores = model.predict(pairs[:stage_size * 3])
doc_scores = list(zip(current_docs[:stage_size * 3], scores))
doc_scores.sort(key=lambda x: x[1], reverse=True)
current_docs = [doc for doc, _ in doc_scores[:stage_size]]
# 最后一轮精细排序
pairs = [(query, doc) for doc in current_docs]
scores = model.predict(pairs)
results = list(zip(current_docs, scores))
results.sort(key=lambda x: x[1], reverse=True)
return [
{"content": doc, "score": float(score)}
for doc, score in results[:stages[-1]]
]4.2 混合检索+Rerank
将关键词检索和向量检索的结果合并,再进行Rerank:
def hybrid_search_with_rerank(query: str, vector_top_k: int = 50, keyword_top_k: int = 50, final_top_k: int = 5):
"""混合检索 + Rerank"""
# 向量检索
query_vector = embed_model.embed_query(query)
vector_results = milvus.search(data=[query_vector], limit=vector_top_k)
vector_docs = [r["entity"]["content"] for r in vector_results[0]]
# 关键词检索(使用BM25)
keyword_results = bm25_retriever.search(query, limit=keyword_top_k)
keyword_docs = [r["content"] for r in keyword_results]
# 合并去重
all_docs = []
seen = set()
for docs in [vector_docs, keyword_docs]:
for doc in docs:
if doc not in seen:
all_docs.append(doc)
seen.add(doc)
# Rerank
reranked = rerank_documents(query, all_docs, top_k=final_top_k)
return reranked4.3 Rerank结果的置信度过滤
Rerank分数可以用于判断结果的置信度:
def retrieve_with_confidence(query: str, threshold: float = 0.3):
"""基于Rerank分数的置信度过滤"""
results = rerank_documents(query, candidate_docs, top_k=10)
# 过滤低置信度结果
confident_results = [r for r in results if r["score"] >= threshold]
if not confident_results:
return {
"status": "low_confidence",
"message": "未找到高置信度相关文档,建议转人工处理"
}
return {
"status": "success",
"results": confident_results
}五、Rerank调优指南
5.1 评估指标
Rerank效果的评估指标与普通检索类似,重点关注:
MRR@K:相关文档首次出现的位置越靠前,MRR越高。
NDCG@K:综合考虑相关度和排名位置的评估指标。
Precision@K:最终返回的K个结果中有多少是真正相关的。
5.2 常见问题排查
问题:Rerank后效果反而变差
- 检查Top-K向量检索的候选数量是否足够(通常需要Top-50~100)
- 检查Rerank模型的领域是否匹配(如医疗场景需要用医疗数据微调的模型)
- 尝试不同的Rerank模型(如bge-reranker-large vs bge-reranker-base)
问题:Rerank速度太慢
- 使用量化版本的模型(如int8量化)
- 减少向量检索候选数量
- 采用分层Rerank策略
问题:部分类型查询效果差
- 分析低分案例,看看是向量检索召回问题还是Rerank排序问题
- 针对特定类型Query进行专项优化
六、总结与行动建议
今天的文章系统讲解了Rerank技术在RAG系统中的核心价值和应用方法。
核心要点回顾:
Rerank解决的是向量检索”精度不够”的问题。通过更精细的语义理解,Rerank能够从候选集中筛选出真正相关的内容。向量检索负责”广覆盖”,Rerank负责”精准挑”——二者配合是RAG系统的标准范式。
BGE-Reranker是目前中文场景最推荐的Rerank模型,开源免费、效果优异、配套完善。对于英文场景或有快速验证需求的场景,Cohere Rerank API是不错的选择。
集成Rerank时需要注意:候选数量要足够(Top-50~100),避免在向量检索阶段就过滤掉了正确答案;Rerank后的Top-K设置要根据实际需求调整,通常5~10个足够生成答案。
今日行动建议:
1. 本地实验:使用BGE-Reranker对现有RAG系统进行Rerank改造,观察效果提升
2. 模型对比:尝试不同的Rerank模型,对比找出最适合你场景的选择
3. 参数调优:调整Top-K向量候选数量,观察对最终效果的影响
4. 置信度实践:基于Rerank分数实现置信度过滤,提升系统可靠性
下期预告:Day15我们将进入《完整RAG项目实战》。我们会综合运用前14天学到的所有知识,从项目规划、环境搭建、数据处理、到系统部署,完整构建一个生产级别的RAG应用。30天进阶实战系列精彩继续,敬请期待!