

很多人用了 ChatGPT、Claude、文心一言、豆包大半年,还是不敢说”我懂 AI”。
不是工具不熟,是底层概念没打通。Token 是什么、上下文窗口多大算够、RAG 怎么让 AI 知道”我家狗叫旺财”、Agent 跟普通对话有什么区别——这些词天天见,但很少有人能 5 分钟讲清楚。
2026 年是 AI 工程师的”概念年”。Anthropic 6 月刚发了 Fable 5(虽然 72 小时就被美国政府下架了,参见我们 6/14 的分析)、OpenAI 计划本月发 GPT-5.6、谷歌开源了 Gemma 4 12B、DeepSeek 把百万 Token 价格降到了按厘计价——行业正在以天为单位迭代。
不会这些概念,用 AI 就是”看运气”;会了,你才能判断哪个工具值不值得订阅、哪篇教程值不值得读、哪个 Agent 平台真正能落地。
这篇文章的目标就一个:用 5000 字,把 6 个最常被混用的概念讲透。读完你应该能:
- 看产品宣传页时立刻知道它在卖什么
- 和开发者/产品经理对话时不用反复问术语
- 自己判断”这个 AI 工具有没有真本事”还是”换皮炒作”
一、Token:AI 世界的”字符”,但不是字
💡 Token 不是”字”,是 AI 模型处理文字的最小单位。你可以把它想成”模型自己造的字”。
比如这句话:”今天天气真好”。人类看到 6 个字,但 GPT 这类模型可能切分成 [“今天”, “天气”, “真”, “好”] 共 4 个 Token。中文一个字大约对应 1-2 个 Token,英文一个单词大约对应 1-3 个 Token(依模型而异)。
为什么这个概念重要?两个原因:
第一,所有 API 都按 Token 收费。DeepSeek 现在的定价是 1 元/百万 Token(输入),1 元 = 100 万 Token = 大约 70 万个中文字符。换算下来,写一篇 5000 字的稿子让 DeepSeek 读一遍只花 7 分钱。Claude Opus 4.8 大约 15 元/百万 Token,差距 15 倍。
第二,模型有上下文窗口上限。Claude Opus 4.8 是 200K Token(约 15 万字),GPT-5.x 是 128K-1M,Gemini 3.5 Pro 最高支持 2M Token(约 150 万字,能塞进一整本《三体》)。这个上限决定”模型一次能读多少东西”。
1.1 Token 的两种角色:输入和输出
很多人分不清”输入 Token”和”输出 Token”的区别。简单说:
- 输入 Token:你发给模型的内容(问题 + 上下文),按”读取量”收费
- 输出 Token:模型生成的回答,按”生成量”收费,通常比输入贵 3-5 倍
举例:你用 Claude 让它读 1000 字文章并写 500 字总结。输入约 1500 Token,输出约 750 Token,账单 = 输入价×1500 + 输出价×750。所以”让 AI 写长篇大论”很贵,简洁的提示词工程能直接省一半钱。
1.2 怎么估算 Token 数?
- 在线工具:OpenAI Tokenizer(platform.openai.com/tokenizer)、DeepSeek Tokenizer(platform.deepseek.com/tokenizer)
- 代码:用
tiktoken(OpenAI 官方库)或transformers(Hugging Face)库自动算 - 经验值:英文 1 单词 ≈ 1.3 Token,中文 1 字 ≈ 1.5 Token,代码 1 行 ≈ 10-30 Token
实操建议:
- 计费用 Token 不用换算,记住”百万 Token 几分到几十元”这个量级就行
- 处理长文档前先估算 Token 数(工具:OpenAI Tokenizer、DeepSeek Tokenizer)
- 上下文窗口不是越大越好——越大越贵,且”长上下文注意力衰减”是真的
- 提示词能简短就简短,输出能用结构化(JSON/表格)就别让 AI 写散文
二、上下文窗口:AI 的”短期记忆”
💡 上下文窗口就是模型一次对话能”看见”的所有内容。超出窗口的内容,模型”不记得”。
举个真实场景。你在 Claude 里粘贴了一本 50 万字的小说,然后问”女主角最后嫁给谁了”。如果上下文窗口只有 100K Token(大约 7 万字),模型只能看到小说的前 1/7,第 5 章之后的剧情它”看不见”,所以会瞎编。
2026 年的上下文军备竞赛:
| 模型 | 上下文窗口 | 大约能装 |
|---|---|---|
| Claude Opus 4.8 | 200K | 1 本长篇小说 |
| GPT-5.x | 128K-1M | 5-40 本小说 |
| Gemini 3.5 Pro | 2M | 200 本小说 |
| Llama 4 | 10M(实验) | 1000 本小说 |
| Kimi K2.7 | 200K | 1 本小说 |
看起来越大越好,但有两个陷阱:
- 长上下文注意力衰减——研究显示,模型在超长上下文里对中间和末尾的内容理解精度会下降(俗称”中间丢失”现象)。2M Token 不是真”全记住”,是”大致能扫到”。
- 成本线性增长——输入 1M Token 和输入 10K Token,价格差 100 倍。盲目塞长文档,账单会爆。
2.1 上下文窗口的”注意力衰减”实测
Google DeepMind 2024 年发过一项研究叫”Needle in a Haystack”(大海捞针),专门测模型在长上下文里对不同位置信息的检索能力。结果非常直观:
- 上下文开头 10%:检索准确率 95%+
- 上下文中部 50%:检索准确率掉到 70-80%
- 上下文末尾 10%:回升到 90%+
这就是为什么很多人发现”AI 经常忘记中间说过的话”——不是模型真的忘了,是注意力机制天然对中间内容不敏感。
实操建议:
- 长文档处理优先用”分块 + 检索”(后面讲的 RAG),而不是硬塞
- 关键信息放在上下文开头或结尾,模型注意力最强
- 用 Gemini 3.5 Pro 这种长上下文模型做”先粗读后精读”
三、提示词:怎么让 AI “听懂人话”

💡 提示词(Prompt)就是你发给 AI 的指令。提示词工程(Prompt Engineering)就是研究”怎么写指令,AI 才能输出你想要的东西”。
它和”对话”的区别:普通用户是把 AI 当聊天工具,想到哪说到哪;提示词工程师是把 AI 当”会听话但理解力有限的外包”,需要清晰、结构化、给示例。
3.1 CO-STAR 框架详解
最经典的提示词公式(CO-STAR 框架):
Objective(目标):写 3 条朋友圈推广文案
Style(风格):口语化、有梗、不超过 50 字
Tone(语气):热情但不油腻
Audience(受众):25-35 岁的产品经理
Response(格式):每条用"【标题】+正文"格式
加上这个框架,输出质量比”帮我写个朋友圈文案”高 3-5 倍。
框架每个字母的拆解:
- Context(背景)——给 AI “前情提要”,让模型知道它在什么场景下工作
- Objective(目标)——明确说”要做什么”,而不是”想做什么”
- Style(风格)——规定文风(学术/口语/幽默/严肃)
- Tone(语气)——规定情感色彩(热情/中性/批判)
- Audience(受众)——给 AI 想象一个具体的读者画像
- Response(格式)——规定输出结构(表格/列表/JSON/段落)
3.2 5 个必学的进阶技巧
- Few-Shot(给示例):写”参考:’凌晨3点改bug,天亮了’,按这个风格再写 3 条”
- 思维链(CoT):写”请一步步思考,先列大纲,再写正文”
- 角色设定:写”你是乔布斯,请用他的风格评价这个产品”
- 负面约束:写”不要用’赋能’、’闭环’、’抓手’这三个词”
- 多轮迭代:第一次输出后,给反馈”第2条不够幽默,请更口语化”
我们 aizxs.com 4 月份的【Prompt 炼金术】Day1-Day10 系列(ID 4353-5218)专门讲过这些技巧,值得一读。提示词工程这个领域 2023 年是热门,2024-2025 年进化到 Context Engineering(上下文工程),2026 年又往前推到 Agentic Prompt(让 AI 自主设计提示词)。
实操建议:
- 简单任务用”角色+任务+约束”3 段式
- 复杂任务加 Few-Shot 示例(3-5 个最好)
- 输出不理想时,先改提示词,再换模型——90% 的问题出在提示词
四、Embedding:让 AI “理解”语义的魔法
💡 Embedding(嵌入)是把”一段文字”变成”一组数字”的过程。相似的文字,数字也相似。
4.1 Embedding 的工作原理
这是 AI 最反直觉的能力。人类理解”高兴”和”开心”意思差不多是天然能力,但计算机不懂。它需要把每个词、每句话变成一个 768 维或 1536 维的向量(可以理解为”一串 768 个数字组成的坐标”),然后用数学方法算”两个向量的距离”——距离近的意思相近,距离远的无关。
举个真实例子。句子 A:”猫在沙发上睡觉”,句子 B:”猫咪在躺椅上休息”,句子 C:”今天股票跌了”。
- A 和 B 的 Embedding 向量距离:0.05(很近)
- A 和 C 的距离:0.85(很远)
Embedding 背后的数学:用的是余弦相似度(Cosine Similarity),公式是 cosθ = (A·B) / (||A||×||B||),结果范围 [-1, 1],越接近 1 越相似。这个公式衡量的是”两个向量的方向一致程度”,比欧氏距离更适合文本。
4.2 三个核心应用场景
- 语义搜索——用户搜”苹果手机”,能匹配到”iPhone 15″的文章,不用关键词完全一样
- 推荐系统——读完一篇”大模型入门”,推荐”Embedding 原理”,因为向量近
- RAG(下一节)——把文档变成向量存起来,问问题时找最相关的几段塞进提示词
4.3 主流 Embedding 模型对比
| 模型 | 维度 | 价格 | 特点 |
|---|---|---|---|
| OpenAI text-embedding-3-small | 1536 | 0.02 美元/百万 Token | 综合最强 |
| OpenAI text-embedding-3-large | 3072 | 0.13 美元/百万 Token | 精度更高 |
| BGE-M3 | 1024 | 开源免费 | 中文友好 |
| M3E | 1536 | 开源免费 | 国内常用 |
| Cohere embed-v3 | 1024 | 0.1 美元/百万 Token | 多语言 |
实操建议:
- 选 Embedding 模型主要看”中文效果”和”速度”,不用追新
- 向量维度不是越大越好,1536 维对绝大多数场景够用
- Embedding 不是”完美语义理解”——它只是统计意义上的相似度
- 中文场景优先 BGE-M3 或 M3E,跨语言场景用 Cohere
五、RAG:让 AI 知道”它不知道的事”
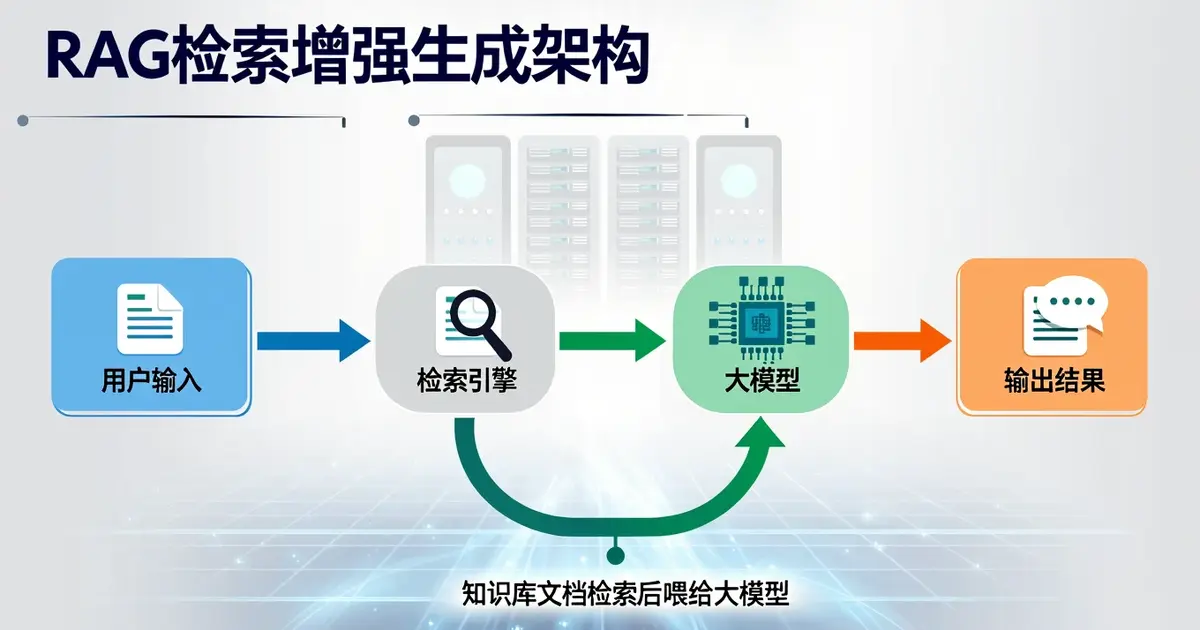
💡 RAG(Retrieval-Augmented Generation,检索增强生成)= 先用 Embedding 检索相关文档,再让 AI 基于检索结果生成回答。
为什么需要 RAG?大模型有三大局限:
- 知识截止——训练数据有截止日期,问它”今天天气”它不知道
- 私有知识盲区——它没读过你公司的内部文档
- 幻觉——它会一本正经地胡说八道
RAG 的解决思路很朴素:问问题时,先去知识库里搜最相关的 3-5 段资料,然后塞进提示词说”请基于以下资料回答:[资料1][资料2][资料3]”。
5.1 完整 RAG 流程拆解
↓
1. 把问题变成 Embedding 向量
↓
2. 在向量数据库里找 Top 5 最相关的文档段落
↓
3. 把这 5 段塞进提示词:
"请基于以下资料回答用户问题。
资料 1:…
资料 2:…
资料 3:…
用户问题:…"
↓
4. LLM 基于资料生成回答
↓
5. 返回结果(带引用)
5.2 RAG 三大件详解
- Embedding 模型(上一节):把文字变向量
- 向量数据库(Vector DB):存和检索向量,主流有 Milvus、Chroma、Qdrant、Pinecone
- 重排序(Rerank):初步检索 Top 100,再用更精细的模型重排取 Top 5,精度大幅提升
5.3 5 个 RAG 进阶方向
- 混合检索——向量检索 + 关键词检索(BM25)结合,召回率提升 20%
- 父子分段——把文档切成大段(500 字)和小区(100 字),检索小区时返回大段,平衡精度和上下文
- HyDE(Hypothetical Document Embeddings)——先用 LLM 假设一个理想答案,再拿这个假设答案去检索
- Self-RAG——让 LLM 自己判断”这个资料够不够回答问题”,不够就重新检索
- Agentic RAG——让 Agent 决定”查几次、查哪里”,自主完成多跳推理
我们 aizxs.com 在 4 月份的【进阶实战】Day11-Day15(ID 2925-3117)专门拆过 RAG 全流程,【高级应用】Day8-Day10(ID 4150-4154)讲过企业级实践,值得深入读。
实操建议:
- 任何”问公司内部知识”的场景,优先考虑 RAG,不要先 Fine-tuning
- 起步用 Chroma(轻量)或 Milvus(生产级),别上来就上 Pinecone
- Rerank 是 RAG 效果的关键——预算够就上 BGE-Rerank
- 文档分块大小很重要——300-500 字一段最稳
六、Agent:让 AI “动手做事”而不只是”说话”
💡 Agent(智能体)= 能”自己规划任务、调用工具、执行动作”的 AI 系统。普通 AI 是”问什么答什么”,Agent 是”给它目标,自己想办法搞定”。
普通 AI 对话 vs Agent:
- 普通 AI:你问”北京今天天气怎么样?”,它说”我没有实时数据”
- Agent:你问”北京今天天气怎么样?”,它自己调天气 API、查数据、生成回答
6.1 一个真实 Agent 的执行过程
假设你说:”帮我订明天去上海的最便宜机票”。
Agent 内部流程:
- 理解目标:订明天(2026-06-16)从北京到上海的最便宜机票
- 规划任务:① 查航班列表 ② 比价 ③ 选最便宜的 ④ 调支付 API
- 调用工具:调用 Skyscanner API 查航班 → 拿到 20 个航班
- 执行决策:用 LLM 分析价格,选 870 元那班(最便宜但不是红眼)
- 执行动作:调用航司 API 完成下单(需要你提前授权支付)
- 反馈结果:”已订 CA1856,明天 08:30 起飞,870 元”
整个过程完全自主,不需要你一步步指挥。这就是 Agent 和普通 AI 的本质区别——普通 AI 是”问答机器”,Agent 是”会自己想办法的执行者”。
6.2 Agent 三大核心能力
- 任务规划——把”帮我订明天去上海的机票”拆成”查航班→比价→下单→填信息”
- 工具调用(Function Calling/Tool Use)——主动调用外部 API/工具执行动作
- 记忆与反思——记住之前做了啥,做错了能重试
主流 Agent 框架(2026 年):
| 框架 | 厂商 | 特点 |
|---|---|---|
| LangGraph | LangChain | 灵活,适合复杂工作流 |
| AutoGen | 微软 | 多 Agent 协作 |
| CrewAI | 开源 | 角色化 Agent 团队 |
| Coze | 字节 | 零代码,国内最易上手 |
| Dify | 开源 | 低代码,企业级 |
| Manus | 中国创业 | 通用 Agent(已被 Meta 收购,参见 ID 3292) |
MCP 与 A2A 协议:Anthropic 2024 年开源了 MCP(Model Context Protocol),让 Agent 能像 USB-C 一样标准化连接各种工具;Google 牵头搞了 A2A(Agent-to-Agent),让不同 Agent 互相通信。这是 2025-2026 年 Agent 生态最重要的两个标准(我们在 4/6 的【进阶实战】Day17 详细介绍过,ID 3282)。
Agent 不是万能的——它解决的是”多步骤、需要外部信息、有明确目标”的任务。如果是简单问答、纯文本生成,Agent 反而画蛇添足。
实操建议:
- 零基础先从 Coze 扣子入门(5 分钟搭客服机器人)
- 有开发基础从 LangGraph 或 Dify 入手
- 企业级用 Dify 或阿里云 Cloud Agents
- 警惕”通用 Agent”宣传——能稳定解决 1 个垂直问题的 Agent,比号称”什么都能做”的 Agent 有用 10 倍
七、6 个概念怎么串起来

讲完 6 个概念,最后给一张”全家福”,帮你建立整体认知:
│
├─ 1. Token 阶段:先把问题切成 Token,模型才能理解
│
├─ 2. 提示词阶段:把"请基于资料回答"写进 Prompt(提示词工程)
│
├─ 3. Embedding 阶段:把问题变成向量
│
├─ 4. RAG 阶段:
│ ├─ 用向量在知识库检索 Top 5 相关段落
│ ├─ 用 Rerank 精排取 Top 3
│ └─ 把这 3 段塞进 Prompt
│
├─ 5. 上下文窗口阶段:所有内容塞进模型窗口(不能超过 200K Token)
│
└─ 6. Agent 阶段(可选):
├─ 模型判断"需要查内部工单系统"
├─ 调用 Tool Use 查工单
└─ 综合检索 + 工单数据,生成回答
记住这个心法:
- Token = 计费单位
- 上下文窗口 = 短期记忆容量
- 提示词 = 你和 AI 的”沟通协议”
- Embedding = 把文字变向量的”翻译官”
- RAG = 给 AI 配”随身资料库”
- Agent = 让 AI “动手”而不是”动嘴”
7.1 一张图看 AI 工程师的技能栈
│ 应用层:Agent / 多模态 / 行业解决方案 │
├─────────────────────────────────────────┤
│ 能力层:RAG / Function Calling / Memory │
├─────────────────────────────────────────┤
│ 模型层:GPT-5.x / Claude / Gemini / DeepSeek │
├─────────────────────────────────────────┤
│ 基础层:Token / 上下文 / Embedding / 向量DB │
├─────────────────────────────────────────┤
│ 协议层:MCP(工具) / A2A(Agent间) │
└─────────────────────────────────────────┘
你是开发者,先把基础层(Token/上下文/Embedding)搞懂,再学能力层(RAG/Function Calling),最后用应用层(Agent/多模态)解决业务问题。我们这个 AI 学习栏目 4 月份发的【进阶实战】30 天系列、【高级应用】30 天系列,就是按这个路径设计的。
八、5 个常见误区
最后列 5 个最常踩的坑,对照自查:
误区 1:上下文窗口越大越好——其实注意力衰减是真实的,2M Token 塞满后中间内容识别率下降 20-30%。先用 RAG 检索,再塞上下文,比”硬塞全文”效果好。
误区 2:RAG 越复杂越好——起步一个 Chroma + 一个 Embedding 模型 + 一个 LLM 就够了。引入 GraphRAG、多跳检索、Agentic RAG 之前,先把基础 RAG 的召回率提到 80% 以上。
误区 3:Agent 能解决一切——Agent 适合”多步骤 + 需要外部信息”的任务。纯文本生成、简单问答用普通对话更高效。
误区 4:提示词工程是”玄学”——不是。提示词工程有可学习的框架(CO-STAR/CRISPE/BROKE),也有可量化的评估方法。先学框架,再迭代。
误区 5:Fine-tuning 比 RAG 好——对 90% 的企业场景,RAG 优于 Fine-tuning。Fine-tuning 贵、难维护、且需要大量标注数据。除非你有大量行业语料且场景固定,否则先做 RAG。
8.1 进阶误区:3 个 2026 年新坑
- “用了 MCP 就万事大吉”——MCP 是工具调用标准,但工具本身设计得烂,MCP 也救不了你。工具要选”高频、原子化”的,避免一个工具包含 10 个功能。
- “上下文工程就是写更好的 Prompt”——Context Engineering 远不止写好提示词,还包括上下文结构(消息顺序)、记忆机制(短期/长期)、信息密度(去重/压缩)三层。
- “Embedding 模型越新越好”——Hugging Face MTEB 榜单上”最新第一”的模型,在你的业务数据上可能不如用了 2 年的 BGE-M3。先 benchmark,再选型。
九、动手清单
读完这篇,建议你做这 3 件事:
1. 注册一个 RAG 玩具项目(30 分钟)——用 Dify(dify.ai)部署一个本地知识库,喂 5 篇你公司的产品文档,问 3 个问题验证效果。
2. 跑通本地大模型(20 分钟)——安装 Ollama(ollama.com),执行 ollama run qwen2.5:7b,在终端和本地大模型对话,对比 API 体验。
3. 拆解 1 个 Agent 应用(1 小时)——选一个你常用的 AI 工具(Coze 机器人 / 飞书智能伙伴 / 微信 AI 助手),试着画出它的”任务规划 + 工具调用 + 记忆”流程图。
9.1 推荐 6 本入门书(按难度分级)
🟢 零基础:《这就是 ChatGPT》(Stephen Wolfram 著,通俗科普)、《大模型应用开发极简入门》(Olivier Caron 著)
🟡 进阶:《Hands-On Large Language Models》(Jay Alammar 著,配图极好)、《Designing Machine Learning Systems》(Chip Huyen 著,工程视角)
🔴 高级:《Designing Data-Intensive Applications》(Martin Kleppmann 著,数据系统圣经)、《AI Engineering》(Chip Huyen 2025 新书,AI 工程化最佳实践)
如果你对 2026 年最值得读的 AI 书单感兴趣,我们 aizxs.com 6 月 10 日发过一篇《2026 年 AI 学习必读 8 本书》(ID 8471),每本都附 GitHub 下载链接。
十、参考资料
本文涉及的核心概念来自以下权威来源:
- Token & 上下文窗口:OpenAI 官方文档 platform.openai.com/docs、Anthropic 官方文档 docs.anthropic.com
- Embedding 模型:Hugging Face MTEB Leaderboard(huggingface.co/spaces/mteb/leaderboard)、OpenAI Embeddings 文档
- RAG 框架:LangChain 官方文档 python.langchain.com、Pinecone Learning Center(pinecone.io/learn)
- Agent 框架:LangGraph 文档 langchain-ai.github.io/langgraph、Anthropic MCP 文档 modelcontextprotocol.io
- MCP 协议:Anthropic 2024 年 11 月开源标准,2025-2026 年成为行业事实标准
其他延伸阅读:
- Anthropic《Building effective agents》(2024 年 12 月)—— Agent 设计的奠基性文章
- OpenAI《Practical Guide to Building Agents》(2025 年)—— Agent 实操指南
- LangChain《RAG From Scratch》系列教程 —— RAG 从入门到精通
- aizxs.com【进阶实战】Day11-Day15 RAG 系列(ID 2925-3117)—— RAG 中文实战
- aizxs.com【AI Agent 开发实战】Day1-Day6 系列(ID 7705-7802)—— Agent 中文实战
附:从 6 个概念出发的完整学习路径
学完这 6 个概念后,按这个顺序往下学,3 个月可以从”会聊天”到”能做项目”:
第 1 个月:基础工具上手
- Week 1-2:注册 ChatGPT/Claude/Gemini,用日常任务练习提示词工程
- Week 3-4:学 Coze / Dify 零代码平台,搭 1-2 个简单 Bot
第 2 个月:开发能力入门
- Week 5-6:学 Python 基础 + 调用 LLM API(OpenAI/DeepSeek SDK)
- Week 7-8:学 RAG 基础,用 LlamaIndex 或 LangChain 搭一个本地知识库
第 3 个月:Agent 实战
- Week 9-10:学 Function Calling / Tool Use,自己写一个简单 Agent
- Week 11-12:学 MCP 协议,给 Agent 接外部工具(数据库/浏览器/代码执行)
3 个月后,你可以独立做”AI 工具应用”项目——这是 2026 年最抢手的能力栈。如果你想加速,我们 aizxs.com 6 月 7-11 日发的【AI 编程实战】5 篇系列(ID 8353-8382)就是按这个路径设计的,从 Claude Code 到 Dify 到 Codex CLI,每篇都附完整可运行代码。
互动话题
你日常用 AI 工具时,遇到最多困惑的是哪个概念?是”Token 怎么算钱”、”上下文窗口多大合适”、”RAG 怎么做”,还是”Agent 怎么选型”?
评论区聊聊,呼声最高的话题我单独写一篇深度拆解。




我要评论
登录后即可发表评论