


【进阶实战】Day11:RAG原理深度解析——让AI拥有”长期记忆”的核心技术
大模型很聪明,但有一个致命缺陷:它只知道训练时学到的知识,不知道你公司的内部规定,不了解昨天的新闻,更看不懂你上传的私有文档。这就是所谓的”幻觉问题”——AI在你不熟悉领域信誓旦旦地编造答案。
解决这个问题有两个主要思路:一是Fine-tuning(微调),让模型重新学习新知识;二是RAG(检索增强生成),给模型配一个”实时查阅的参考资料”。今天我们深度解析RAG的原理,让你掌握这项大模型落地最重要的技术。
一、为什么大模型需要RAG
大语言模型本质上是”概率生成机器”。它们在预训练阶段学习了海量文本的统计规律,能够根据输入的提示词预测下一个最可能的词。然而,这种能力带来三个根本性局限:
知识时效性问题:模型的知识截止于训练时间点。今天发生的新闻、新颁布的法规、刚刚更新的产品文档,模型统统不知道。询问ChatGPT”今天有什么大事”,它只能老实承认自己不知道。
私有知识盲区问题:模型的训练数据主要是公开互联网内容。企业的内部流程、医疗记录、财务数据、客服话术——这些从未出现在训练集中的私有知识,模型完全无法理解和利用。
幻觉问题:由于模型本质上是在”猜”下一个词,当它对某个领域不够了解时,会倾向于编造看似合理但实际上是错误的内容。这就是为什么AI有时会”一本正经地胡说八道”。
针对这些问题,Fine-tuning和RAG提供了不同的解决思路。Fine-tuning相当于”让专家重新上学”,成本高、周期长,而且每次知识更新都需要重新训练。RAG则相当于”给专家配一本实时更新的手册”,成本低、见效快,而且知识可以随时更新。
二、RAG的核心原理
RAG全称Retrieval-Augmented Generation,中文译为检索增强生成。它的核心理念是:不修改模型本身,而是在模型生成答案之前,先从外部知识库中检索出与问题相关的真实资料,再将这些资料作为上下文交给模型进行回答。
可以理解为:让大模型实现”开卷考试”,只依据给定资料作答,不再凭空想象。
RAG的工作流程分为两个主要阶段:离线构建阶段和在线检索阶段。
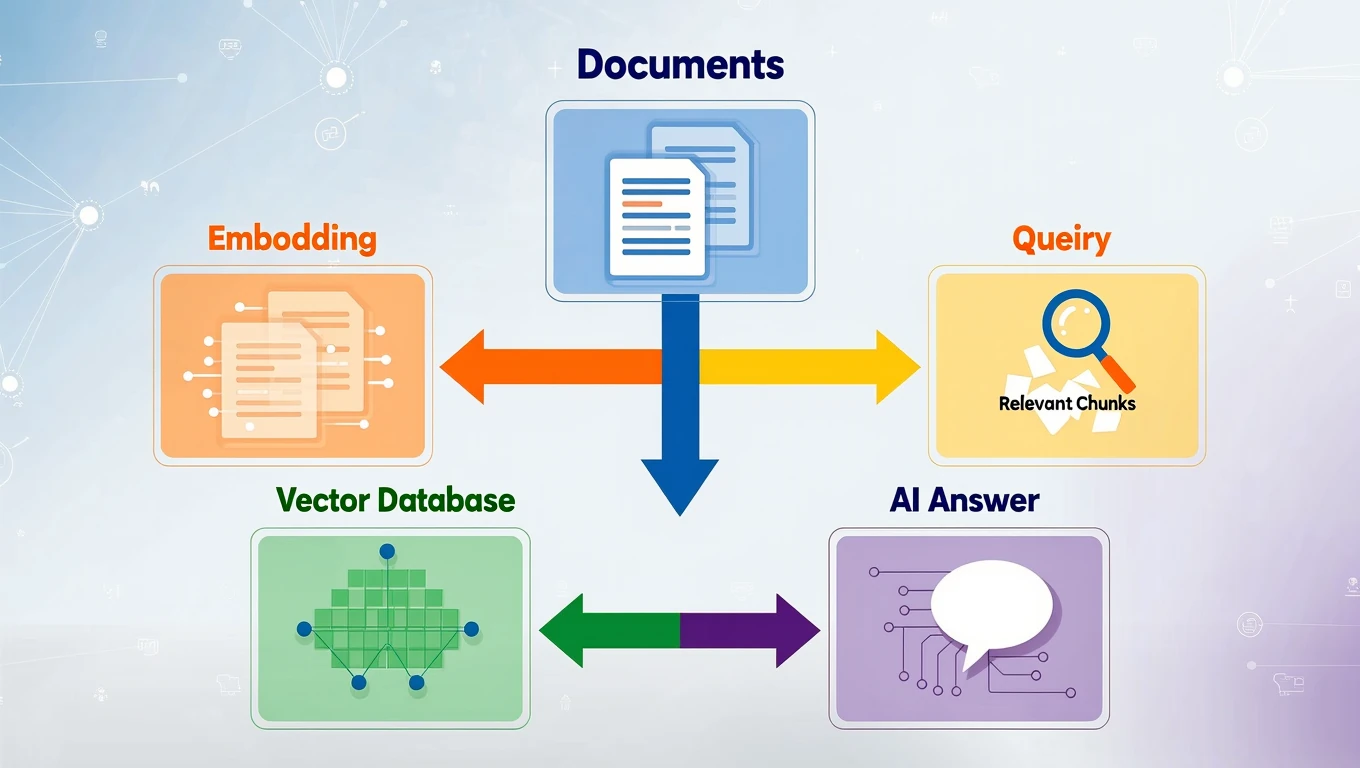
离线构建阶段负责将原始文档处理成可检索的格式。具体步骤包括:首先加载各种格式的文档(PDF、Word、网页等),然后将长文档切分成较小的文本块(Chunk),接着使用Embedding模型将每个文本块转换成向量,最后将这些向量和原始文本存入向量数据库。
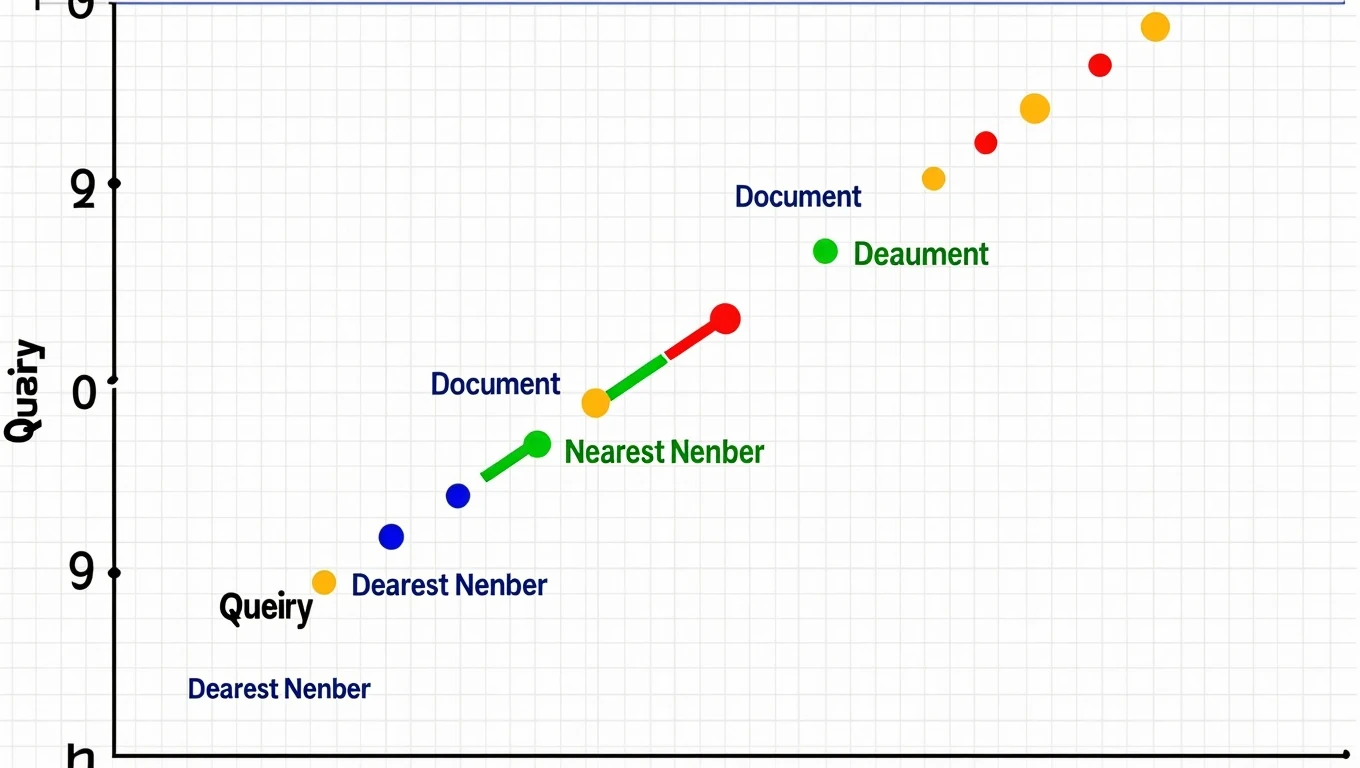
在线检索阶段负责回答用户的实时查询。用户提出问题后,系统将问题同样转换成向量,然后在向量数据库中进行相似度搜索,找到与问题最相关的K个文本块,将这些文本块与原始问题组合成增强Prompt,交给大模型生成最终答案。
三、RAG的三大核心组件
3.1 文档处理与分块
文档处理是RAG系统的第一道工序。原始文档可能来自PDF、网页、数据库、API等不同来源,需要统一转换成文本格式。这一步看似简单,实际上直接影响后续检索的质量。
分块(Chunking)是将长文档切成小段的过程。为什么要切?因为向量模型对输入长度有限制,而且小段落更容易精确定位相关内容。常见的分块策略包括固定长度分块(按字数或词数切分)、语义分块(按段落或章节切分)、递归分块(按层次结构递归切分)。
分块大小的选择很关键:太大则包含过多噪声,降低检索精度;太小则丢失上下文,信息不完整。常见的策略是使用512-1024个token的块大小,并保留相邻块之间的重叠以维持上下文连贯性。
3.2 向量化与Embedding

向量化是RAG的灵魂操作。Embedding模型的作用是将文本转换成密集向量,使得语义相似的文本在向量空间中距离更近。
当用户询问”如何重置密码”时,如果数据库中有”找回账户密码的步骤”这个文本块,由于两句话语义相近,它们的向量表示也会很接近,向量检索就能准确匹配到这条内容。
主流的Embedding模型包括OpenAI的text-embedding-ada-002、 Cohere的embed-multilingual、以及国产的文心Embedding等。选择模型时需要考虑效果、速度、成本和多语言支持等因素。
3.3 向量数据库
向量数据库是存储和检索向量的专门系统。常见的向量数据库包括Pinecone(云服务)、Milvus(开源)、Chroma(轻量级)、Weaviate等。
向量检索的核心是相似度计算。常用的相似度度量方式包括余弦相似度(Cosine Similarity)、点积(Dot Product)和欧氏距离(Euclidean Distance)。余弦相似度衡量两个向量的方向夹角,更适合文本语义相似度场景;点积同时考虑向量大小和方向,适合需要考虑检索词频率的场景。
四、RAG的高级技巧
4.1 混合检索
单纯的向量检索有时会遇到问题:精确关键词匹配无法完成,比如搜索”FAQ#123″这样的规范术语时,向量相似度可能很低。
混合检索结合了向量检索和关键词检索(BM25)的优点。关键词检索基于词频统计,精确匹配能力强;向量检索语义理解能力强。两者结合,通过 Reciprocal Rank Fusion(RRF)等算法融合结果,往往能获得比单独使用更好的效果。
4.2 重排与过滤
初步检索返回的结果可能包含不相关或噪声内容。重排(Reranking)模型,如Cohere的Rerank或BGE-M3,可以进一步评估检索结果与问题的相关性,对结果进行二次排序。
同时,可以设置过滤规则排除低质量内容。比如设定相似度分数阈值,只返回分数超过0.7的结果;或者根据文档来源、更新时间等元数据进行过滤。
4.3 查询扩展与改写
用户的自然语言问题有时与知识库中的表述方式不同。查询扩展技术通过同义词替换、问题分解等方式,让检索更容易命中相关内容。
比如用户问”公司年假怎么休”,可以扩展为”年假请假制度请假流程年假政策”等多个检索词同时检索,再合并结果。
五、RAG与Fine-tuning的对比
很多人在选择RAG还是Fine-tuning时感到困惑。简单来说,两者的适用场景不同。
RAG的优势在于:知识可实时更新(修改文档即可),可解释性强(答案来源于哪个文档一目了然),成本低(无需重新训练模型),隐私性好(私有数据不必上传训练)。
Fine-tuning的优势在于:模型行为更稳定(不依赖外部检索),响应更快(无需检索步骤),适合学习特定风格或模式。
实际应用中,两者并非互斥。很多高级系统会结合使用:用RAG提供实时知识,用Fine-tuning调整模型的行为风格和响应模式。
六、RAG的局限性与未来发展
RAG虽强,但也有局限。检索质量依赖知识库的构建质量,如果文档组织混乱或分块不合理,检索效果会大打折扣。多次检索和模型调用的链路延迟较高,对实时性要求高的场景不友好。多跳推理能力有限,面对需要跨多个文档综合推理的复杂问题,纯RAG可能表现不足。
未来的发展方向包括:多模态RAG(支持图像、表格、音视频等多种模态的检索)、Agent化RAG(让Agent自主决定何时检索、检索什么、如何整合信息)、流式RAG(边检索边生成,减少等待时间)等。
七、实战建议
如果你准备在项目中使用RAG,建议从以下几个方面入手:
首先是明确需求。是要让AI回答基于私有文档的问题?还是让AI实时获取最新资讯?不同的目标对应不同的系统设计。
其次是重视数据质量。RAG的效果很大程度上取决于知识库的质量。在开始技术实现之前,先花时间整理和清洗数据,比后期优化算法更有效。
第三是从简单开始。先用基础RAG架构跑通整个流程,验证可行性后再逐步引入混合检索、重排等高级特性。
第四是持续监控和优化。RAG系统的效果需要持续监控,包括检索召回率、答案准确率、用户满意度等指标,根据监控数据不断迭代优化。
RAG是当前大模型落地最实用、最有效的技术方案。掌握RAG的原理和实践,是每一位AI开发者必备的核心技能。在接下来的Day12-15中,我们将继续深入讲解向量数据库、Rerank、企业知识库搭建和完整RAG项目实战,敬请期待。


我要评论