


如果前三篇(Claude Code / Cursor / Coze)解决的是「怎么用 AI 写代码、搭零代码应用」,那 Dify 解决的是另一个问题:怎么把 AI 应用真正落地到生产环境。
这一篇是【AI编程实战】系列的第四篇(前三篇是 Claude Code、Cursor、Coze,下一篇是 Codex CLI),我们用 Dify 1.0 搭一个企业级私有知识库:从 Docker 部署、知识库配置、工作流编排、API 对接,到生产环境上线,1 个下午能跑通。
适合人群:有后端基础、负责 AI 应用落地的开发者、技术负责人、想给团队/客户交付 AI 应用的创业者。
一、为什么是 Dify:生产就绪的 LLM 应用平台的 3 个真实价值
在开始装之前,先回答一个常见问题:既然有了 Coze 零代码平台,为什么还要学 Dify?
1.1 不是零代码玩具,是「生产就绪」平台
据 Dify 官方 GitHub README,Dify 自我定位是「Production-ready platform for agentic workflow development」(来源:github.com/langgenius/dify)。注意两个关键词:
- Production-ready:能扛生产流量,不是 Demo 级
- Agentic workflow:核心是工作流编排,不是聊天
这和 Coze(零代码、轻量级)形成了清晰的差异化:Dify 面向的是「要在生产环境跑 AI 应用」的团队。
1.2 跟 Coze 的本质区别:私有化 + 深度可控
Coze 适合个人和小团队快速搭应用,但有几个限制:
- 数据在 Coze 平台(国内版在字节)
- 二次开发能力有限
- 高级特性需要商业版
Dify 的优势是:
- 完全开源(Dify Open Source License,基于 Apache 2.0)
- 私有化部署:数据完全在你自己服务器
- 深度可定制:工作流节点、插件、API 全部可扩展
- 生产级观测:对接 Opik、Langfuse、Arize Phoenix(来源:github.com/langgenius/dify)
简单说:Coze 是「在别人家搭积木」,Dify 是「在自家盖房子」。
1.3 谁在用它:从个人开发者到企业生产
据 Dify 官方 README,Dify 已被全球开发者广泛使用,GitHub 上持续活跃(具体 Star 数随时变化,建议去仓库看实时数据,来源:github.com/langgenius/dify)。
Dify 支持私有化部署到 Kubernetes(社区贡献了多个 Helm Chart)、AWS、Azure、阿里云等多种环境(来源:github.com/langgenius/dify)。
这意味着 Dify 不是「Demo 工具」,已经过了大型生产环境的验证。
💡 工具会过时,但「开源 + 私有化部署 + 可观测」这个组合,正在成为企业级 AI 应用的默认选项。
💡 看再多教程,不如跑通一个真实项目——这是学企业级 AI 应用最快的方式。
💡 「生产就绪」不是营销词,意味着要扛住并发、保证数据安全、能够观测——这才是 Dify 的核心价值。
二、官方文档核心概念解读
这一节专门讲清楚 Dify 的几个关键概念,后面用起来不迷糊。资料全部来自 Dify 官方 GitHub 和文档(docs.dify.ai)。
2.1 什么是 Agentic Workflow
Agentic Workflow(智能体工作流)是 Dify 的核心概念。和传统「一问一答」聊天不同,工作流是:
用户输入 → 节点1(检索) → 节点2(LLM) → 节点3(工具调用) → 输出
每个节点完成一个特定任务,节点之间可以分支、循环、并行。这种编排方式可以做出非常复杂的应用,比如:
- 多轮对话机器人
- 数据处理管道
- 自动化报告生成
- 多 Agent 协作系统
2.2 Dify 的工作原理:可视化 + 可扩展
据 Dify 官方 README,Dify 平台的设计理念是「intuitive interface combines AI workflow, RAG pipeline, agent capabilities, model management, observability features」(来源:github.com/langgenius/dify)。
作为用户,你在 Web 界面拖拽节点、配置参数;底层,Dify 通过 API 调度各种 LLM、调用外部工具、存储到数据库。
2.3 核心能力:7 大功能模块
据 Dify 官方 README,Dify 提供 7 大核心能力(来源:github.com/langgenius/dify):
- Workflow:可视化画布上构建和测试强大的 AI 工作流
- Comprehensive model support:无缝集成数百种 LLM(GPT、Mistral、Llama3,以及所有 OpenAI API 兼容模型)
- Prompt IDE:直观的提示词编写界面
- RAG Pipeline:从文档摄入到检索的完整 RAG 能力,支持 PDF、PPT 等格式
- Agent capabilities:基于 LLM Function Calling 或 ReAct 定义 Agent,内置 50+ 工具(Google Search、DALL·E、Stable Diffusion、WolframAlpha 等)
- LLMOps:监控和分析应用日志和性能
- Backend-as-a-Service:所有功能都有对应 API,轻松集成到业务系统
2.4 当前最新版本:1.0+(1.0 系列)
据 Dify 官方博客和文档,Dify 1.0 是当前的稳定大版本。1.0 系列相比 0.x 有几个关键改进:
- 知识库检索增强(自定义元数据过滤)
- Parent-child Retrieval(父子分段检索)
- Hybrid Search(混合搜索)+ Rerank
- Citations(引用归因)
具体版本号可以在 GitHub Releases 查看实时数据(来源:github.com/langgenius/dify/releases)。
三、5 分钟极速部署
这一节带你用 Docker 部署 Dify 1.0。
3.1 系统要求
据 Dify 官方 README,部署 Dify 的最低要求(来源:github.com/langgenius/dify):
- CPU:≥ 2 Core
- 内存:≥ 4 GiB
- 磁盘:≥ 20 GiB(知识库会占空间)
- 环境:Docker + Docker Compose
- 操作系统:Linux / macOS / Windows(WSL2)
3.2 安装 Docker
macOS:下载 Docker Desktop(https://www.docker.com/products/docker-desktop),按向导装。
Linux(以 Ubuntu 为例):
sudo apt update
sudo apt install docker.io docker-compose
sudo usermod -aG docker $USER
Windows:装 Docker Desktop,启用 WSL2 后端。
3.3 部署 Dify
打开终端,执行:
git clone https://github.com/langgenius/dify.git
cd dify/docker
cp .env.example .env
docker compose up -d
第一次启动会拉镜像、构建容器,可能需要 5-10 分钟。
3.4 验证部署
启动成功后,在浏览器打开:
http://localhost/install
首次访问会进入初始化向导:
1. 设置管理员账号密码
2. 配置公司名称
3. 完成后进入 Dify 工作台
3.5 生产环境部署建议
如果要在生产环境跑(不是本地测试),官方推荐(来源:github.com/langgenius/dify):
- Kubernetes 部署:用社区贡献的 Helm Chart(github.com/douban/charts 等)
- AWS Marketplace:Dify Premium on AWS Marketplace(AMI 镜像,一键部署到 AWS VPC)
- 阿里云:阿里云计算巢(Compute Nest)一键部署
- Azure:用 Terraform 部署
注意:生产环境需要额外配置:
- HTTPS(用 Nginx 反向代理)
- 数据库备份(Dify 用 PostgreSQL)
- 监控告警(用 Grafana 接入 Dify 的 PostgreSQL)
💡 部署只是开始——备份、监控、HTTPS 才是「生产」和「测试」的分水岭。
四、实战项目:企业级私有知识库(核心教程)
理论讲完,直接动手。我们用 Dify 搭一个企业级私有知识库,场景设定:
- 一家有 200 人的公司,产品手册、操作指南、内部流程文档散落在 Confluence、飞书、Notion
- 员工经常问”请假流程怎么走?”、”VPN 怎么配?”、”XX 系统的入口在哪?”
- 搭一个 AI 助手,基于内部文档回答,7×24 小时在线
4.1 项目需求拆解
我们的目标:
- 员工通过 Web 界面提问
- AI 基于公司内部文档回答
- 答案附带文档引用(可点击查看原文)
- 不知道答案时,引导联系对应同事
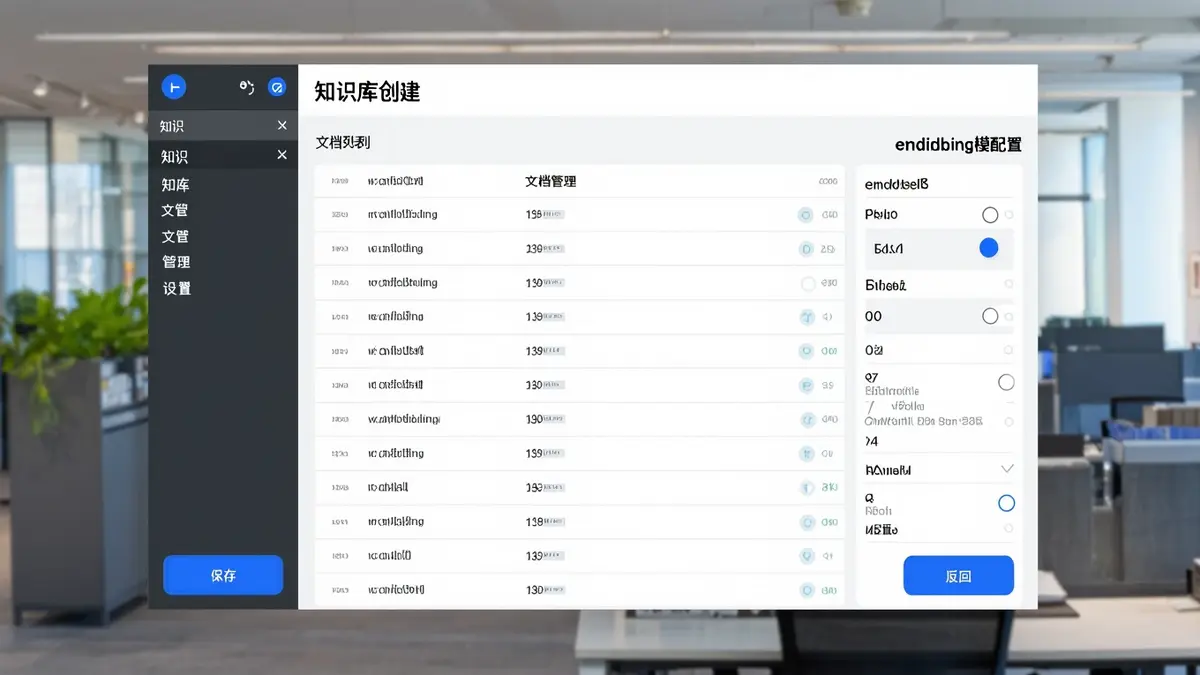
4.2 第一步:创建知识库
进入 Dify 工作台,点击「知识库」→「创建知识库」:
1. 知识库名称:公司内部知识库
2. 数据源:
- 从文件导入:上传 PDF/Word/Markdown(适合小批量)
- 从 Notion 同步:授权 Notion 工作区,自动同步
- 从 Web 站点同步:爬取指定 URL(比如 Confluence 公开页面)
- 通过 API 同步:对接 Confluence、飞书等系统(高级)
3. 文本分段模式:
- 通用模式:Dify 自动按段落分段(推荐新手)
- 父子模式:父段 + 子段,检索子段时关联到父段(精度更高)
- QA 模式:专门为问答对优化(适合 FAQ)
4. Embedding 模型:选 OpenAI text-embedding-3-small 或 bge-m3(开源)
5. 检索设置:
- 向量检索(默认,语义相似度)
- 全文检索(关键词匹配)
- 混合检索(两者结合,推荐)
4.3 第二步:上传文档
以「从文件导入」为例:
1. 准备 3-5 个示例文档:
- `员工手册.pdf`(15 页,讲请假流程、报销规则)
- `IT系统操作指南.md`(讲 VPN、邮件系统、考勤)
- `产品文档.md`(讲核心功能、API 列表)
2. 上传到知识库
3. Dify 自动解析、分段、向量化(这一步可能要 1-2 分钟)
4. 完成后,在「文档列表」能看到所有文档和分段
4.4 第三步:创建 Chatflow 应用
知识库有了,接下来要建一个能用的应用。
1. 进入「工作室」→ 点「创建空白应用」
2. 应用类型选 Chatflow(支持多轮对话 + 工作流)
3. 应用名称:公司内部 AI 助手
4. 进入编排页面
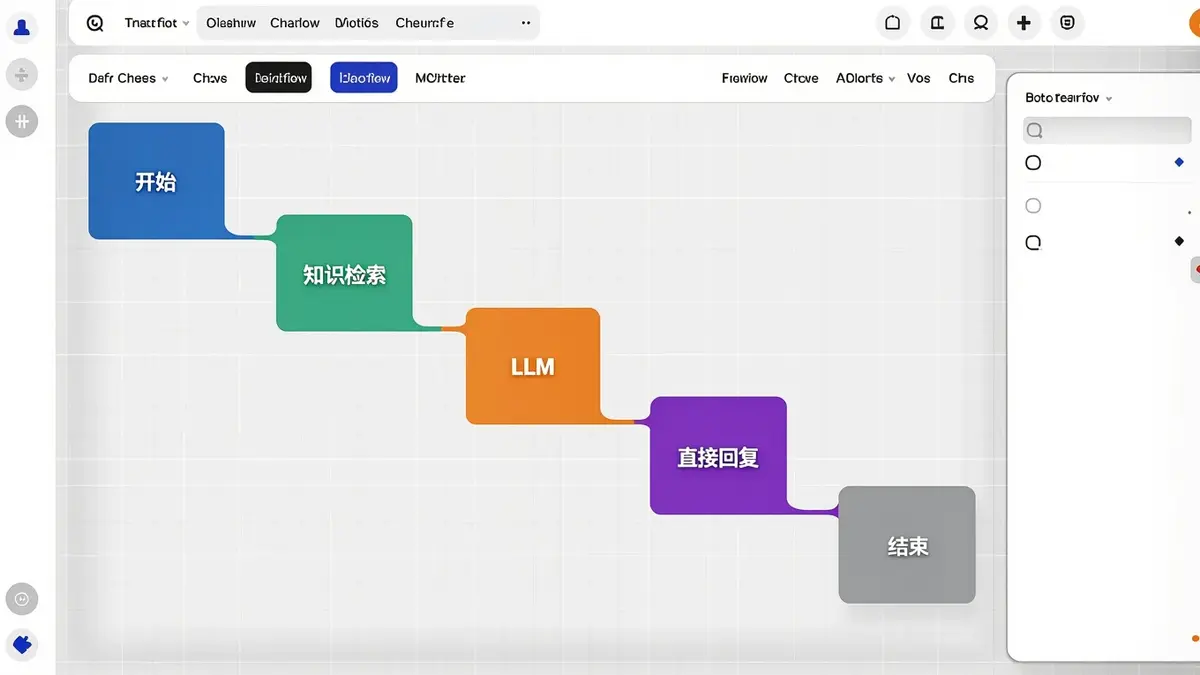
4.5 第四步:编排工作流
在 Chatflow 编排页,我们加几个核心节点:
1. 开始节点(系统自带)
- 接收用户输入的问题
2. 知识检索节点
- 关联刚才创建的「公司内部知识库」
- 设置 Top K = 3(返回 3 个最相关分段)
- 设置 Score 阈值 = 0.5(过滤低相关度)
3. LLM 节点
- 模型选 GPT-4 / Claude 3.5 / DeepSeek(看你自己的 API key)
- 系统提示词:
你是公司的内部 AI 助手,基于提供的知识库内容回答员工问题。
规则:
1. 严格基于知识库内容回答,不编造
2. 引用时用 [1][2] 这样的标记
3. 不知道答案时说"这个问题我暂时答不上,建议联系对应同事"
4. 语气友好、简洁
- 用户提示词模板:
知识库内容:
{{#context#}}
员工问题: {{#sys.query#}}
请基于上述知识库内容回答。
4. 直接回复节点
- 输出 LLM 的回答
- 包含引用(References)
5. 结束节点
4.6 第五步:调试和优化
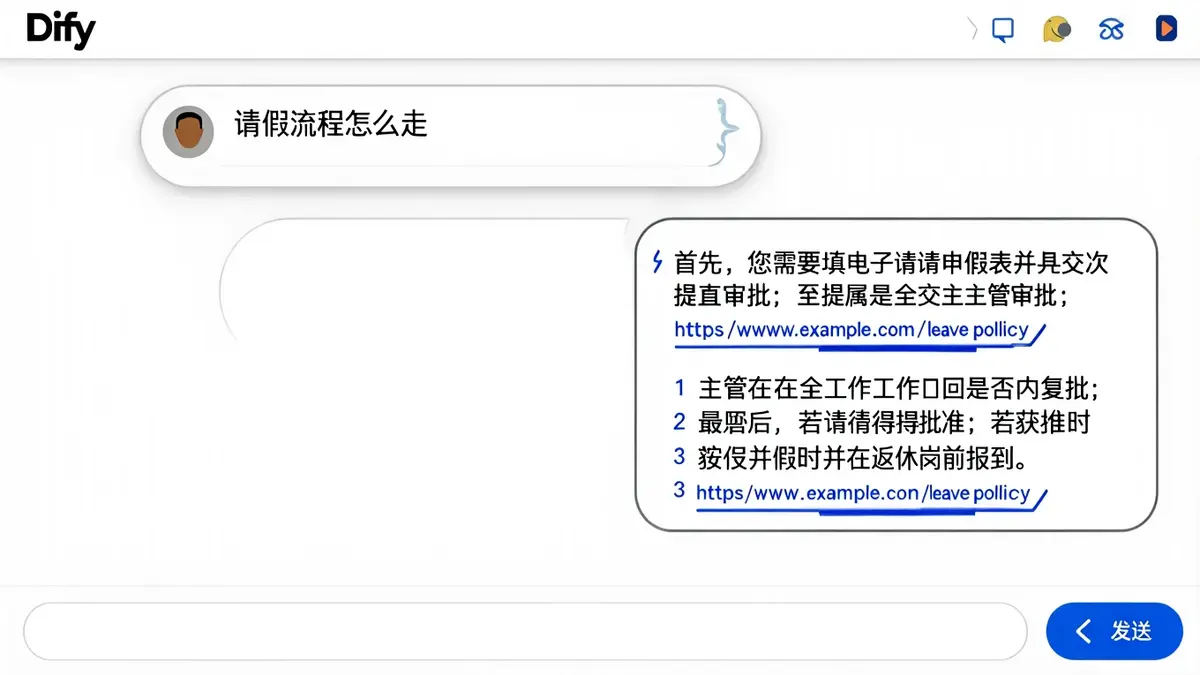
1. 在右侧「调试」面板测试:
- 问”请假流程怎么走?”→ 应该引用员工手册
- 问”VPN 怎么配?”→ 应该引用 IT 指南
- 问”今天天气怎么样?”→ 应该回答不知道
2. 看答案质量:
- 引用是否准确?
- 答案是否自然流畅?
- 不知道时是否正确兜底?
3. 调整参数:知识检索 Score 阈值、LLM temperature 等
4.7 第六步:发布应用
调试满意后,点「发布」,Dify 提供 4 种发布方式:
- WebApp:直接生成一个 Web 链接,员工浏览器访问
- API:返回标准 OpenAI 兼容的 API
- 嵌入到网站:用 iframe 嵌入到公司内网
- 企业微信/飞书机器人:对接 IM(需要额外配置)
WebApp 是最简单的方式,发布后员工直接在浏览器用。
4.8 完整工作流配置参考
下面是更完整的 Chatflow 配置:
节点1:开始(接收 sys.query)
节点2:知识检索(公司内部知识库,Top K=3,Score≥0.5)
节点3:判断
- 条件 1:检索结果非空 → 进入 LLM 节点
- 条件 2:检索结果空 → 进入「兜底回复」节点
节点4:LLM(基于知识库内容回答,带引用)
节点5:直接回复(输出答案 + 引用列表)
节点6:兜底回复(回答不知道,引导加人工)
节点7:结束
💡 跟传统开发比,Dify 让你不用写检索代码、不用接 LLM API、不用管数据库——拖拖拽拽就搭好了,而且可以直接私有化部署。
💡 跑通一个小项目,比读十篇教程更有用——这是学 Dify 的「最小可执行单元」。
💡 RAG 的质量,80% 取决于文档分段 + 检索策略,LLM 只占 20%——别指望换个更强模型就能解决答案不准的问题。
五、进阶用法:3 个真实提效技巧
基础 Chatflow 跑通后,这几个进阶用法能让你做出更专业的工作流。
5.1 多知识库路由:不同部门不同知识库
实际企业中,HR、IT、销售、研发每个部门都有自己的文档。可以用「问题分类」节点先判断用户想问什么,再路由到对应知识库:
节点1:开始
节点2:问题分类(LLM 分类:HR/IT/产品/其他)
节点3:分支
- HR → HR 知识库 → LLM → 输出
- IT → IT 知识库 → LLM → 输出
- 产品 → 产品知识库 → LLM → 输出
- 其他 → 兜底回复
节点4:结束
这样每个部门的答案都精准。
5.2 父子分段检索:长文档精度更高
Dify 1.0 引入了 Parent-child Retrieval(父子分段检索,来源:dify.ai/blog/introducing-parent-child-retrieval-for-enhanced-knowledge)。
原理:把长文档切成”父段 + 子段”,检索时匹配子段(更精准),但返回给 LLM 时是父段(上下文更完整)。
设置方法:在知识库「索引模式」里选「父子分段」,设置父段长度(如 2000 字符)、子段长度(如 400 字符)。
5.3 观测和优化:对接 Langfuse
据 Dify 官方 README,Dify 支持对接 Langfuse、Opik、Arize Phoenix 等可观测性平台(来源:github.com/langgenius/dify)。
配置方法:
1. 部署 Langfuse(https://langfuse.com)
2. 在 Dify 的 .env 文件里配置 Langfuse 的 API key
3. 重启 Dify
4. 在 Langfuse 控制台能看到所有请求的 trace
这样你能看到:
- 每次问答的耗时
- LLM 用了多少 token
- 检索命中率
- 用户反馈
💡 进阶用法不是炫技,而是「让 AI 应用可观测、可优化」——这是生产环境和 Demo 的本质区别。
💡 父子分段不是为了炫技,是为了解决「检索精准但上下文丢失」的实际问题。
六、6 个真实踩坑案例
教程写得再漂亮,实际部署的时候总会有意外。
6.1 坑 1:Embedding 模型配置错误
症状:知识库上传成功,但检索时一个答案都查不到。
原因:Embedding 模型没配置,或者 API key 错了。
解决:
1. 进入「设置」→「模型供应商」,确认 Embedding 模型已配置
2. 测试 API key 是否有效
3. 删除知识库重建,重新上传文档
6.2 坑 2:文档解析失败,内容乱码
症状:上传 PDF 后,知识库里的内容是乱码或空白。
原因:PDF 是扫描件(图片型),Dify 默认只能解析文本型 PDF。
解决:
1. 用 OCR 工具先把扫描件转成文本 PDF
2. 或在 Dify 知识库里手动粘贴文本
3. 或换成 Markdown/Word 格式上传
6.3 坑 3:检索结果太多,答案跑题
症状:用户问”请假流程”,AI 答案里混入了报销、考勤等不相关内容。
原因:Top K 太大,或 Score 阈值太低。
解决:
1. Top K 从 5 降到 3
2. Score 阈值从 0.3 提到 0.5
3. 用「元数据过滤」缩小范围(给文档打标签,比如”HR 类”)
6.4 坑 4:LLM 节点超时
症状:每次回答都要等 30 秒以上,体验很差。
原因:LLM 选了大模型(如 GPT-4),或者网络问题。
解决:
1. 切换到更快模型(如 GPT-3.5-turbo、DeepSeek)
2. 减少 LLM 输入的 context 长度
3. 加流式输出(在 LLM 节点配置)
6.5 坑 5:WebApp 移动端样式丑
症状:WebApp 在手机上打开,文字挤在一起,体验差。
原因:Dify 默认 WebApp 模板是桌面端优先。
解决:
1. 在「WebApp 设置」里开启「移动端适配」
2. 或在「嵌入到网站」里用 iframe + 响应式 CSS 自己套
3. 直接调用 API 自己做前端
6.6 坑 6:多用户并发,PostgreSQL 扛不住
症状:几个用户同时用,Dify 报数据库连接错误。
原因:默认 PostgreSQL 配置是单机版,并发能力有限。
解决:
1. 切换到外部 PostgreSQL(比如阿里云 RDS)
2. 调大 PostgreSQL 连接池
3. 加 Redis 缓存(在 .env 里配)
七、举一反三:3 个可改造的扩展项目
企业知识库只是入门。掌握了这个套路,你可以改造成各种行业应用。
7.1 改成法律咨询助手
知识库:上传法律法规、判例、合同模板
工作流:问题分类 → 检索 → LLM → 加免责声明
注意:法律建议是高风险场景,必须加「这是 AI 建议,具体请咨询律师」的兜底。
7.2 改成医疗问答助手
知识库:医学指南、药品说明书、临床路径
工作流:症状识别 → 知识检索 → 回答 → 紧急情况跳转 120
注意:医疗 AI 必须有人工审核兜底,不能直接给诊断。
7.3 改成金融研报助手
知识库:上市公司年报、行业研报、宏观经济数据
工作流:问题分类 → 检索 → 数据提取 → 生成图表(用 Dify 的代码执行节点)
注意:金融数据有合规要求,确保数据来源合法。
八、常见问题 Q&A
8.1 Dify 完全免费吗?
Dify 开源版(Community Edition)完全免费,但需要自己服务器部署;云服务版按月订阅,免费 200 message credits(来源:dify.ai/pricing)。
8.2 Dify 和 Coze 怎么选?
- Coze:零代码,适合个人/小团队快速搭应用
- Dify:可私有化,适合企业/有数据合规要求的团队
简单判断:数据要出不了公司 → 选 Dify;数据无所谓 → Coze 更省事。
8.3 Dify 部署难吗?
Docker Compose 一键部署,需要懂基础的 Docker 命令。Kubernetes 部署比较复杂,推荐用社区 Helm Chart。
8.4 数据会泄露吗?
私有化部署时,所有数据都在你自己服务器,不会上传到 Dify 官方。云服务版数据由 LangGenius 公司存储,具体看他们的隐私政策。
8.5 Dify 支持哪些模型?
据官方 README,Dify 支持「数百种专有/开源 LLM,涵盖 GPT、Mistral、Llama3,以及任何 OpenAI API 兼容模型」(来源:github.com/langgenius/dify)。
具体列表:https://docs.dify.ai/getting-started/readme/model-providers
8.6 怎么升级 Dify?
cd dify
git pull
cd docker
docker compose up -d
升级前务必备份数据库!
8.7 Dify 适合多大团队?
- 1-10 人:Dify 社区版完全够用
- 10-100 人:Dify 社区版 + 单独的 PostgreSQL
- 100 人以上:Dify 企业版或 Premium on AWS
8.8 Dify 的可观测能力够用吗?
对中小团队够用(应用日志、性能监控都在内置 LLMOps 里)。对大型企业,建议对接 Langfuse 或 Arize Phoenix。
九、官网与下载链接
- Dify 官网:https://dify.ai
- GitHub 开源仓库:https://github.com/langgenius/dify
- 官方文档:https://docs.dify.ai
- 定价页面:https://dify.ai/pricing
- 博客:https://dify.ai/blog
- Discord 社区:https://discord.gg/FngNHpbcY7
- Docker Hub:https://hub.docker.com/u/langgenius
部署方式汇总:
| 方式 | 难度 | 适合场景 |
|---|---|---|
| Docker Compose | ⭐⭐ | 本地测试、小团队 |
| Kubernetes + Helm | ⭐⭐⭐⭐ | 中大型生产 |
| AWS Marketplace | ⭐⭐ | AWS 用户一键 |
| Azure Terraform | ⭐⭐⭐ | Azure 用户 |
| 阿里云计算巢 | ⭐⭐ | 阿里云用户 |
| 官方云服务 | ⭐ | 不想运维的团队 |
云服务订阅价格(据 dify.ai/pricing 2026 年 6 月):
| 计划 | 价格 | 关键指标 |
|---|---|---|
| Sandbox | 免费 | 200 message credits,1 成员,5 Apps |
| Professional | $59/月 | 5,000 credits,3 成员,50 Apps |
| Team | $159/月 | 10,000 credits,50 成员,200 Apps |
十、行动建议 + 互动话题
10.1 三步上手计划
如果你是第一次接触 Dify,建议按这个顺序走:
第 1 天(30 分钟):用 Docker Compose 部署 Dify,初始化账号,体验工作台。
第 3 天(2 小时):按本教程搭一个企业内部知识库,上传 3-5 份测试文档,跑通「上传文档 → 提问 → 答案带引用」完整链路。
第 7 天(半天):用真实业务文档(脱敏后)跑通完整流程,接入企业微信/飞书,让真实员工使用,根据反馈优化。
10.2 互动话题
这一篇是【AI编程实战】系列的第四篇(前四篇是 Claude Code、Cursor、Coze、Dify,最后是 Codex CLI)。你在企业里用 Dify 搭过什么应用?私有化部署踩过哪些坑?
欢迎在评论区说说你的体验,下一篇(6/11 Codex CLI)是这一系列的收官之作,会聊聊命令行 AI 编程工具的实战经验。
参考资料:
- Dify GitHub 仓库:https://github.com/langgenius/dify
- Dify 官方文档:https://docs.dify.ai
- Dify 定价:https://dify.ai/pricing
- Dify 知识库文档:https://docs.dify.ai/en/use-dify/knowledge/readme
- Dify 父子分段检索:https://dify.ai/blog/introducing-parent-child-retrieval-for-enhanced-knowledge
- Docker Compose 文档:https://docs.docker.com/compose/
- Langfuse 可观测:https://langfuse.com



我要评论