【高级应用】Day18:多模态应用开发–图文音视频AI应用实战
章节导语
GPT-4V能看图,Gemini能看视频,Whisper能听音频——多模态AI正在重新定义AI的能力边界。不再是”能说会道”,而是”能说会道能看能听能理解”。
但多模态不是简单地把几个模型拼在一起。不同模态的数据格式不同、特征空间不同、语义粒度不同,如何让它们”对齐”是核心难题。
本文系统讲解多模态AI的核心概念和技术方案:从早期融合、晚期融合到层次化融合,从CLIP到Flamingo,从图文对到大一统模型。帮你建立完整的多模态知识体系。
一、前置说明
1.1 学习路径
| 阶段 | 内容 |
|---|---|
| 前置 | Transformer架构(Day5)、注意力机制 |
| 本篇 | 多模态学习与融合 |
1.2 读者需要的基础
- 深度学习基础:理解CNN、RNN、Transformer
- PyTorch基础:能实现简单的模型
- 向量空间概念:理解嵌入、相似度计算
1.3 学习目标
学完本文,你将能够:
- 理解多模态学习的核心挑战
- 掌握不同融合策略的优缺点
- 理解CLIP等经典模型的设计思想
- 实现简单的多模态应用
- 根据场景选择合适的多模态方案

二、多模态学习的核心挑战
2.1 什么是多模态
模态(Modality)是指信息的表现形式。常见模态包括:
- 文本:文字、词语、句子
- 图像:图片、图表、截图
- 音频:语音、音乐、环境声
- 视频:图像序列+音频+时间维度
- 触觉:压力、温度、纹理
多模态学习是指让AI系统能够同时理解和处理多种模态的信息。人类天然是多模态的——我们看书、听音乐、看电影,各种感官信息综合形成完整的体验。AI也在朝这个方向发展。
2.2 核心挑战
多模态学习的核心挑战有三个:
挑战一:异构性
不同模态的数据格式完全不同。文本是离散的符号序列,图像是连续的像素矩阵,音频是连续的波形信号。它们有不同的统计特性、不同的维度、不同的表示方式。如何找到一种统一的表示方式,是第一个难题。
挑战二:关联性
“一只猫在沙发上睡觉”——这句话和一张猫的图片描述的是同一个场景。但文本中的”猫”和图像中的猫像素模式完全不同。如何学习它们之间的对应关系?
挑战三:缺失性
实际场景中,往往不是所有模态都同时可用。比如配图文章,可能只有文字没有图片;比如视频通话,可能只有音频没有视频。如何处理模态缺失?
2.3 发展历程
多模态学习的发展经历了几个阶段:
早期(2014-2016):Image Captioning时代。用CNN提取图像特征,用RNN生成描述文字。代表作Show and Tell。
中期(2017-2019):视觉问答(VQA)时代。LSTM+Attention,让模型能回答关于图片的问题。
近期(2020-2022):CLIP时代。对比学习让图文特征空间统一,多模态任务迎来突破。
当前(2023-):大一统时代。GPT-4V、Gemini等多模态模型,一个模型处理所有模态。

三、融合策略
3.1 早期融合
早期融合(Early Fusion)是在模型最底层把不同模态的特征拼接在一起,然后统一处理。
比如图像和文本:先把图像用CNN提取特征,把文本用Embedding层提取特征,然后拼接成一个向量,输入到后面的网络。
优点:模型可以从一开始就学习模态间的交互,能捕捉到非常细粒度的跨模态关联。
缺点:不同模态的特征往往在不同尺度上发挥作用,早期融合可能过早融合,丢失信息。另外,当模态缺失时处理困难。
3.2 晚期融合
晚期融合(Late Fusion)是在模型高层分别处理各模态,最后在决策层融合。
比如图像分类和文本分类任务:图像分支输出图像的分类概率,文本分支输出文本的分类概率,最后把两个概率向量加权平均或拼接。
优点:各模态可以独立处理,互不干扰;模态缺失时容易处理,缺失哪个分支就只用其他分支。
缺点:无法学习到底层的跨模态关联,融合效果有限。
3.3 层次化融合
层次化融合(Hierarchical Fusion)是早期和晚期的折中,在多个层次上逐步融合。
比如先在底层做图像的局部特征融合,再在中层融合文本和图像的语义特征,最后在高层做最终决策。
优点:兼顾底层关联和高层的语义抽象,更灵活。
缺点:实现复杂度高,需要仔细设计融合层次和方式。
3.4 融合策略对比
| 策略 | 融合层次 | 优点 | 缺点 |
|---|---|---|---|
| 早期融合 | 底层 | 细粒度关联 | 模态缺失难处理 |
| 晚期融合 | 高层 | 模态独立处理 | 关联性弱 |
| 层次化融合 | 多层 | 灵活兼顾 | 复杂度高 |
四、对比学习与CLIP
4.1 对比学习的思想
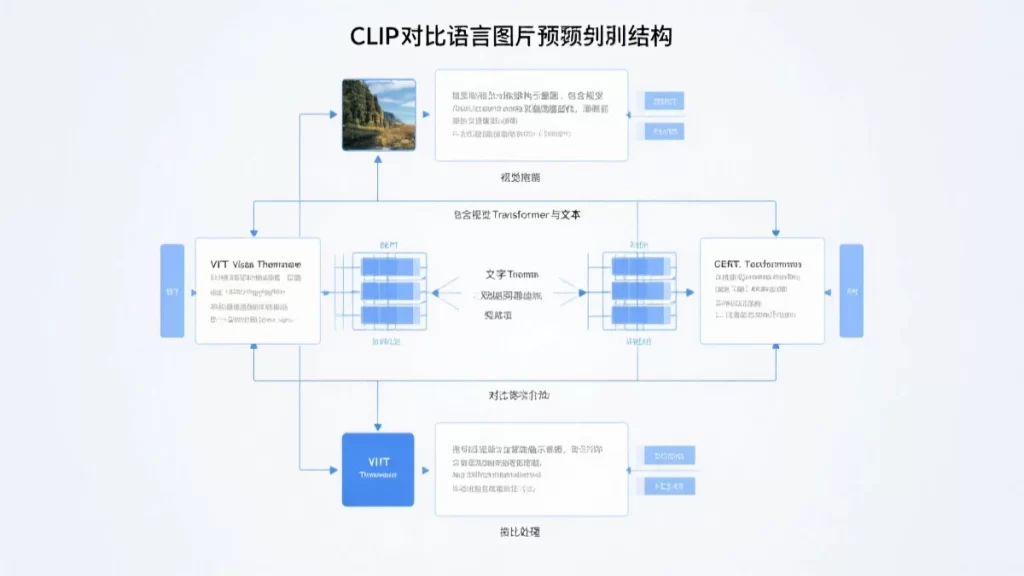
CLIP(Contrastive Language-Image Pre-training)是多模态学习的里程碑。它基于一个简单的思想:让匹配的图文在特征空间中距离近,让不匹配的图文距离远。
训练数据是大量的图文对——互联网上抓取的图片和对应的描述文字。对比学习的目标是:
正样本对:同一张图片和它的描述文字,在特征空间中应该接近。
负样本对:不同图片和描述文字,在特征空间中应该远离。
通过大量的对比学习,模型学会了图文之间的对应关系——”狗”的图片和”a dog”的文字会被映射到特征空间的相近位置。
4.2 CLIP的架构
CLIP由两个编码器组成:
图像编码器:用Vision Transformer(ViT)把图像转换成特征向量。
文本编码器:用Transformer把文本转换成特征向量。
两个编码器输出的向量维度相同,比如都是768维。然后计算文本和图像向量的余弦相似度,匹配的对应该有高相似度。
4.3 CLIP的应用
CLIP训练好后,可以用于多种任务:
零样本图像分类:把类别名称作为文本输入,计算与图像的相似度。这实现了无需训练数据就能分类的能力。
图文检索:根据文本搜索相关图片,或根据图片搜索相关文本。
图像生成引导:Stable Diffusion等图像生成模型用CLIP作为条件引导,控制生成内容。
五、多模态实战
5.1 图像特征提取
import torch
import torch.nn as nn
from PIL import Image
from torchvision import transforms
class ImageEncoder(nn.Module):
"""图像编码器
使用预训练的Vision Transformer提取图像特征
"""
def __init__(self, embed_dim=768):
super().__init__()
# 加载预训练的ViT模型
from torchvision.models import vision_transformer
self.vit = vision_transformer.vit_b_16(weights='IMAGENET1K_V1')
# 去掉分类头,只保留特征提取部分
self.vit.heads = nn.Identity()
# 投影层
self.projection = nn.Linear(768, embed_dim)
self.transform = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
def forward(self, images):
"""提取图像特征
Args:
images: PIL Image或Tensor [B, 3, 224, 224]
Returns:
features: 图像特征向量 [B, embed_dim]
"""
if isinstance(images, PIL.Image.Image):
images = self.transform(images).unsqueeze(0)
with torch.no_grad():
features = self.vit(images)
features = self.projection(features)
return features
def extract(self, image_path):
"""从文件路径提取特征"""
image = Image.open(image_path).convert('RGB')
return self.forward(image)
# 使用
if __name__ == "__main__":
encoder = ImageEncoder()
# 提取单张图片特征
features = encoder.extract("example.jpg")
print(f"图像特征维度: {features.shape}")六、文本特征提取
6.1 文本编码器
import torch
import torch.nn as nn
from transformers import BertTokenizer, BertModel
class TextEncoder(nn.Module):
"""文本编码器
使用预训练的BERT模型提取文本特征
"""
def __init__(self, embed_dim=768):
super().__init__()
self.bert = BertModel.from_pretrained('bert-base-uncased')
self.projection = nn.Linear(768, embed_dim)
# 冻结BERT参数(如果数据少)
# for param in self.bert.parameters():
# param.requires_grad = False
def forward(self, input_ids, attention_mask):
"""提取文本特征
Args:
input_ids: 文本token IDs [B, seq_len]
attention_mask: 注意力掩码 [B, seq_len]
Returns:
features: 文本特征向量 [B, embed_dim]
"""
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
# 使用[CLS] token的特征作为句子表示
pooled_output = outputs.pooler_output
features = self.projection(pooled_output)
return features
class TextProcessor:
"""文本处理工具"""
def __init__(self, max_length=128):
self.tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
self.max_length = max_length
def encode(self, texts):
"""批量编码文本
Args:
texts: 文本列表
Returns:
input_ids, attention_mask
"""
encoding = self.tokenizer(
texts,
padding=True,
truncation=True,
max_length=self.max_length,
return_tensors='pt'
)
return encoding['input_ids'], encoding['attention_mask']
# 使用
if __name__ == "__main__":
text_encoder = TextEncoder()
text_processor = TextProcessor()
# 编码文本
texts = ["a cat sitting on a couch", "a dog running in the park"]
input_ids, attention_mask = text_processor.encode(texts)
# 提取特征
features = text_encoder(input_ids, attention_mask)
print(f"文本特征维度: {features.shape}")七、多模态匹配实战
7.1 图文匹配模型
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultimodalMatcher(nn.Module):
"""图文匹配模型
基于CLIP思想,计算图文相似度
"""
def __init__(self, embed_dim=512, temperature=0.07):
super().__init__()
self.image_encoder = ImageEncoder(embed_dim)
self.text_encoder = TextEncoder(embed_dim)
self.temperature = nn.Parameter(torch.ones([]) * temperature)
def forward(self, images, input_ids, attention_mask):
"""计算图文相似度
Args:
images: 图像张量 [B, 3, 224, 224]
input_ids: 文本token IDs [B, seq_len]
attention_mask: 注意力掩码 [B, seq_len]
Returns:
logits: 图文相似度 [B, B]
"""
# 提取特征
image_features = self.image_encoder(images)
text_features = self.text_encoder(input_ids, attention_mask)
# L2归一化
image_features = F.normalize(image_features, p=2, dim=1)
text_features = F.normalize(text_features, p=2, dim=1)
# 计算余弦相似度
logits_per_image = torch.matmul(image_features, text_features.t()) * torch.exp(self.temperature)
logits_per_text = logits_per_image.t()
return logits_per_image, logits_per_text
def compute_loss(self, logits_per_image, logits_per_text, batch_size):
"""计算对比学习损失
使用交叉熵损失,对角线是正样本
"""
labels = torch.arange(batch_size, device=logits_per_image.device)
loss_image = F.cross_entropy(logits_per_image, labels)
loss_text = F.cross_entropy(logits_per_text, labels)
loss = (loss_image + loss_text) / 2
return loss
# 训练示例
def train_step(matcher, images, input_ids, attention_mask, optimizer):
matcher.train()
optimizer.zero_grad()
batch_size = images.size(0)
logits_per_image, logits_per_text = matcher(images, input_ids, attention_mask)
loss = matcher.compute_loss(logits_per_image, logits_per_text, batch_size)
loss.backward()
optimizer.step()
return loss.item()八、多模态应用
8.1 零样本图像分类
CLIP最厉害的应用之一是零样本分类。不需要训练数据,只需要把类别名称列出来。
比如ImageNet有1000个类别。推理时,把这1000个类别名称都encode成文本特征,然后和图像特征计算相似度,取相似度最高的作为预测类别。
def zero_shot_classify(matcher, image, class_names):
"""零样本图像分类
Args:
matcher: 训练好的多模态模型
image: PIL Image
class_names: 类别名称列表
Returns:
预测的类别名称
"""
# 编码图像
image_features = matcher.image_encoder.extract(image)
image_features = F.normalize(image_features, p=2, dim=1)
# 编码文本(类别名称)
class_texts = [f"a photo of a {name}" for name in class_names]
input_ids, attention_mask = text_processor.encode(class_texts)
class_features = matcher.text_encoder(input_ids, attention_mask)
class_features = F.normalize(class_features, p=2, dim=1)
# 计算相似度
similarities = torch.matmul(image_features, class_features.t())
pred_idx = similarities.argmax(dim=1).item()
return class_names[pred_idx]
# 使用
class_names = ["cat", "dog", "bird", "car", "airplane"]
prediction = zero_shot_classify(matcher, test_image, class_names)
print(f"预测类别: {prediction}")8.2 图像描述生成
多模态模型也可以用于图像描述。但和CLIP不同,这需要解码器生成文本。
常用方案是结合预训练的图像编码器(如ViT)和语言模型(如GPT),在图文数据上做微调。
九、最佳实践
9.1 数据处理
数据平衡:不同模态的数据量要平衡。如果图文对数据中文本描述普遍较短,可能导致文本编码器学得不够好。
数据清洗:图文对数据中有很多噪声,比如图片和文本不相关、文本描述过于简单等。需要仔细清洗。
数据增强:图像可以做随机裁剪、翻转、颜色抖动等增强。但文本增强要小心,改变文本语义会影响学习。
9.2 模型训练
温度参数:对比学习中的温度参数很重要。温度太高,相似度区分度低;温度太低,模型可能崩溃。要通过验证集调优。
批次大小:对比学习需要较大的批次来提供足够的负样本。批次太小,负样本质量差,学习效果不好。
学习率:对比学习的学习率通常比分类任务高。建议使用warmup和余弦衰减。
9.3 评估指标
| 任务 | 指标 |
|---|---|
| 图文检索 | Recall@K、mAP |
| 图像分类 | Top-1/5准确率 |
| 图像描述 | BLEU、CIDEr、SPICE |
十、总结
多模态是AI发展的必然方向。真实世界的信息本身就是多模态的——文本、图像、声音交织在一起。AI要真正理解世界,必须具备多模态能力。
融合策略是核心问题。早期融合、晚期融合、层次化融合各有优劣,要根据任务特点选择。
对比学习是多模态预训练的主流方法。CLIP开创了图文对比学习的范式,后续很多工作都基于此改进。
多模态应用场景丰富。从零样本分类到图像描述,从视频理解到多模态对话,多模态AI正在渗透到各个领域。
延伸阅读
- CLIP论文:Learning Transferable Visual Models From Natural Language Supervision
- BLIP:Bootstrapping Language-Image Pre-training
- GPT-4V:多模态GPT的进展
课后练习
基础题:用CLIP实现一个图文检索系统,给定文本返回最相关的图片。
进阶题:实现一个零样本图像分类器,在5个类别上达到90%以上的准确率。
挑战题:用PyTorch从零实现一个简化版CLIP,包括图像编码器、文本编码器和对比学习损失。