【高级应用】Day17:复杂任务编排与执行–DAG工作流设计艺术
章节导语
把大任务拆成小任务、把多个任务分配给多个Agent、让它们按正确顺序执行、收集结果再汇总——这就是任务编排的艺术。
编排不是简单的”调用函数”。真实场景中,任务之间有依赖关系(任务B必须等任务A完成)、有并行需求(A和B可以同时跑)、有条件分支(根据C的结果决定走D还是E)、有重试机制(失败了要自动重试)。
本文系统讲解任务编排的核心概念和实战技巧,包括DAG工作流、任务分解、依赖管理、并行执行、错误处理等。每个概念都有代码示例。
一、前置说明
1.1 学习路径
| 阶段 | 内容 |
|---|---|
| 前置 | 多Agent系统(Day2)、Agent框架(Day16) |
| 本篇 | 任务编排与工作流 |
1.2 读者需要的基础
- Python基础:异步编程、并发概念
- Agent概念:理解单Agent的执行模式
- 数据结构:图的基本概念(节点、边、拓扑排序)
1.3 学习目标
学完本文,你将能够:
- 理解任务编排的核心概念和适用场景
- 掌握DAG工作流的设计和实现
- 实现任务分解和结果汇总
- 处理并行执行和依赖管理
- 构建容错和重试机制
二、为什么需要任务编排
2.1 简单调用 vs 任务编排
先看一个简单场景:用户要求”帮我写一篇AI文章”。
如果是简单调用,你会写一个Prompt发出去,等一个完整的回答回来。问题来了:写作需要查资料、列大纲、写正文、配图、排版……这些步骤串行执行可能要很长时间,而且每个步骤都可能出错。
如果是任务编排,你会把这个大任务拆成多个子任务:
- 任务A:查资料(可并行:搜索多个来源)
- 任务B:列大纲(等A完成)
- 任务C:写正文(等B完成)
- 任务D:配图(和C可并行)
- 任务E:排版(等C和D完成)
这样设计的好处是:可以并行执行的部分充分利用、依赖关系清晰、错误可以定位到具体任务。
2.2 任务编排的核心能力
一个完善的编排系统应该支持:
任务分解:把大任务拆成小任务,形成树形或图形的任务结构。
依赖管理:定义任务之间的依赖关系,确保执行顺序正确。
并行执行:没有依赖关系的任务可以同时执行,提高效率。
结果汇总:收集子任务的结果,汇总成最终输出。
错误处理:任务失败时的重试、跳过或降级处理。
状态管理:记录每个任务的状态,支持暂停、恢复、取消。
2.3 编排 vs 顺序执行
对比一下两种执行方式的差异:
| 维度 | 顺序执行 | 编排执行 |
|---|---|---|
| 执行时间 | 累加(T1+T2+…+Tn) | 取最大值(max(T1,T2,…) |
| 错误定位 | 难以定位 | 精确到任务 |
| 资源利用 | 低 | 高 |
| 复杂度 | 低 | 高 |
编排的优势在任务复杂、并行空间大时非常明显。但对于简单任务,顺序执行更简单直接。
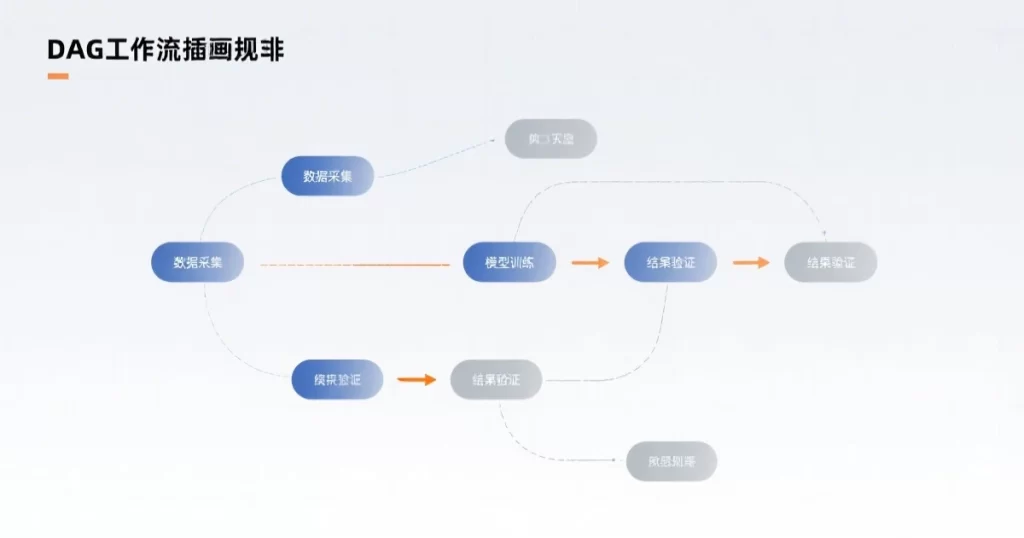
三、DAG工作流
3.1 DAG是什么
DAG(Directed Acyclic Graph,有向无环图)是任务编排的核心数据结构。
有向:边有方向,表示任务的执行顺序。
无环:不能形成闭环,避免死循环。
每个节点是一个任务,每条边表示依赖关系。从入度为0的节点开始,按拓扑排序执行,最终汇聚到出度为0的节点。
3.2 DAG的设计原则
设计DAG时有几个原则:
单一职责:每个任务只做一件事。任务越小,越容易复用、测试、排错。
松耦合:任务之间通过输入输出交互,不直接调用对方。这样任务可以独立修改和替换。
幂等性:任务执行一次和执行多次的结果相同。这让重试机制更安全。
可观测性:每个任务都要有清晰的输入、输出、状态定义,方便监控和调试。
3.3 DAG的执行策略
DAG的执行有几种常见策略:
拓扑排序:按依赖顺序执行。简单但不能并行。
层级并行:同一层的任务并行执行,不同层之间有依赖。常见于MapReduce类任务。
关键路径:识别最长的依赖链,优先保证关键路径的执行。其他任务可以适当延后。
动态调度:根据任务完成情况动态决定下一步执行什么。灵活但复杂。
四、任务分解技术
4.1 何时需要分解
任务不是越小越好。过度分解会增加调度开销和状态管理的复杂度。以下情况需要分解:
任务时间差异大:如果一个任务要10分钟,另一个只要10秒,把它们合并调度效率低。
需要并行:两个独立的长任务分开,可以让它们并行执行。
错误需要隔离:一个大任务失败全部重来,分解后可以只重试失败的部分。
需要条件分支:根据中间结果决定后续走哪条路径。
4.2 分解方法
常见的分解方法:
顺序分解:按执行步骤分解。步骤一、步骤二、步骤三……
并行分解:把可并行的子任务提取出来,同时执行。
递归分解:大任务分解成子任务,子任务如果还复杂就继续分解,直到足够简单。
AI辅助分解:让LLM分析任务,自动提出分解方案。
4.3 结果汇总策略
子任务完成后,结果汇总的方式:
简单拼接:把结果按顺序拼起来。最简单,适合独立的结果。
结构合并:把结果合并成字典或树形结构。适合有层次关系的结果。
聚合计算:对结果进行二次计算,比如求平均、排序、筛选。
条件选择:根据条件选择某个子任务的结果作为最终结果。
五、依赖管理
5.1 依赖类型
任务之间的依赖有几种类型:
数据依赖:任务B需要任务A的输出作为输入。这是最常见的依赖类型。
控制依赖:任务B的执行取决于任务A是否成功完成。A失败时B不应该执行。
资源依赖:任务需要某种资源(GPU、内存、网络),只有资源可用时才能执行。
时间依赖:任务需要在特定时间触发,或者需要在某个前置任务完成后的固定时间后执行。
5.2 依赖冲突
当依赖关系复杂时,可能出现冲突:
循环依赖:A依赖B,B依赖C,C依赖A。无法执行。
依赖缺失:任务B依赖任务A,但A不存在。运行时错误。
依赖冗余:任务同时依赖多个任务,但这些任务有重复计算。
设计时要避免这些问题。可以用依赖图的可视化工具检测循环依赖。
5.3 共享状态管理
多个任务可能需要访问共享状态,比如:
配置信息:所有任务都需要知道的一些全局配置。
中间结果:某些任务的输出是多个后续任务的输入。
计数器:统计已执行的任务数、成功率等。
解决方案:使用分布式存储(Redis)管理共享状态,或者通过消息队列传递。
六、实战:构建任务编排系统
6.1 任务定义
from dataclasses import dataclass, field
from typing import List, Dict, Any, Optional, Callable
from enum import Enum
from datetime import datetime
import asyncio
class TaskStatus(Enum):
"""任务状态"""
PENDING = "pending" # 等待执行
RUNNING = "running" # 执行中
SUCCESS = "success" # 执行成功
FAILED = "failed" # 执行失败
SKIPPED = "skipped" # 被跳过
RETRYING = "retrying" # 重试中
@dataclass
class TaskResult:
"""任务结果"""
task_id: str
status: TaskStatus
output: Any = None
error: Optional[str] = None
start_time: Optional[datetime] = None
end_time: Optional[datetime] = None
retry_count: int = 0
@property
def duration(self) -> float:
"""执行时长(秒)"""
if self.start_time and self.end_time:
return (self.end_time - self.start_time).total_seconds()
return 0
@dataclass
class Task:
"""任务定义"""
task_id: str
name: str
func: Callable # 任务执行的函数
inputs: Dict[str, Any] = field(default_factory=dict) # 输入参数
dependencies: List[str] = field(default_factory=list) # 依赖的任务ID列表
outputs: Dict[str, Any] = field(default_factory=dict) # 输出结果
status: TaskStatus = TaskStatus.PENDING
max_retries: int = 3 # 最大重试次数
timeout: int = 300 # 超时时间(秒)
def can_execute(self, completed_tasks: Dict[str, Task]) -> bool:
"""检查依赖是否都完成"""
for dep_id in self.dependencies:
if dep_id not in completed_tasks:
return False
if completed_tasks[dep_id].status != TaskStatus.SUCCESS:
return False
return True
def get_inputs_from_deps(self, completed_tasks: Dict[str, Task]) -> Dict[str, Any]:
"""从依赖任务获取输入"""
result = {}
for dep_id in self.dependencies:
dep_task = completed_tasks[dep_id]
result[dep_id] = dep_task.outputs
return result七、工作流执行器
7.1 执行器实现
class WorkflowExecutor:
"""工作流执行器
负责:
- 维护任务图
- 按依赖顺序调度任务
- 处理并行执行
- 管理任务状态和结果
"""
def __init__(self, max_parallel: int = 4):
self.tasks: Dict[str, Task] = {}
self.results: Dict[str, TaskResult] = {}
self.max_parallel = max_parallel
self.event_handlers: Dict[str, List[Callable]] = {
'task_start': [],
'task_complete': [],
'task_fail': [],
'workflow_complete': []
}
def add_task(self, task: Task):
"""添加任务"""
if task.task_id in self.tasks:
raise ValueError(f"任务 {task.task_id} 已存在")
self.tasks[task.task_id] = task
def on(self, event: str, handler: Callable):
"""注册事件处理器"""
if event in self.event_handlers:
self.event_handlers[event].append(handler)
def _emit(self, event: str, *args, **kwargs):
"""触发事件"""
for handler in self.event_handlers.get(event, []):
handler(*args, **kwargs)
async def execute_task(self, task: Task) -> TaskResult:
"""执行单个任务"""
task.status = TaskStatus.RUNNING
self._emit('task_start', task)
result = TaskResult(
task_id=task.task_id,
status=TaskStatus.RUNNING,
start_time=datetime.now()
)
try:
# 获取依赖任务的输出作为输入
dep_outputs = task.get_inputs_from_deps(self.results)
# 执行任务(异步)
inputs = {**task.inputs, '_dependencies': dep_outputs}
output = await asyncio.wait_for(
task.func(inputs),
timeout=task.timeout
)
result.output = output
result.status = TaskStatus.SUCCESS
task.status = TaskStatus.SUCCESS
task.outputs = output if isinstance(output, dict) else {'result': output}
self._emit('task_complete', task, result)
except asyncio.TimeoutError:
result.error = f"任务超时({task.timeout}秒)"
result.status = TaskStatus.FAILED
task.status = TaskStatus.FAILED
self._emit('task_fail', task, result)
except Exception as e:
result.error = str(e)
result.status = TaskStatus.FAILED
task.status = TaskStatus.FAILED
self._emit('task_fail', task, result)
result.end_time = datetime.now()
self.results[task.task_id] = result
return result
async def execute(self) -> Dict[str, TaskResult]:
"""执行整个工作流"""
completed = set()
pending = set(self.tasks.keys())
while pending:
# 找出可执行的任务(依赖都已完成)
runnable = []
for task_id in pending:
task = self.tasks[task_id]
if task.can_execute({tid: self.tasks[tid] for tid in completed}):
runnable.append(task)
if not runnable:
# 没有可执行的任务,但还有未完成的
# 可能是循环依赖或前置任务失败
failed = [self.tasks[tid] for tid in pending
if self.tasks[tid].status == TaskStatus.FAILED]
if failed:
break # 有失败任务,退出
raise RuntimeError("任务依赖循环或死锁")
# 限制并发数
runnable = runnable[:self.max_parallel]
# 并行执行
await asyncio.gather(*[self.execute_task(t) for t in runnable])
# 更新完成的任务
for t in runnable:
if t.status == TaskStatus.SUCCESS:
completed.add(t.task_id)
pending.discard(t.task_id)
# 处理失败的任务(可能需要重试)
for t in runnable:
if t.status == TaskStatus.FAILED:
if t.retry_count < t.max_retries:
t.retry_count += 1
t.status = TaskStatus.RETRYING
else:
pending.discard(t.task_id)
self._emit('workflow_complete', self.results)
return self.results
# 使用示例
async def main():
executor = WorkflowExecutor(max_parallel=3)
# 定义任务
def research_task(inputs):
return {"data": ["信息1", "信息2", "信息3"]}
def outline_task(inputs):
deps = inputs['_dependencies']
data = deps.get('research', {}).get('data', [])
return {"outline": ["大纲1", "大纲2", "大纲3"]}
def write_task(inputs):
deps = inputs['_dependencies']
outline = deps.get('outline', {}).get('outline', [])
return {"content": f"写作内容,基于大纲:{outline}"}
def image_task(inputs):
return {"images": ["图1", "图2"]}
# 添加任务
executor.add_task(Task(task_id="research", name="查资料", func=research_task))
executor.add_task(Task(task_id="outline", name="列大纲", func=outline_task, dependencies=["research"]))
executor.add_task(Task(task_id="write", name="写正文", func=write_task, dependencies=["outline"]))
executor.add_task(Task(task_id="image", name="配图", func=image_task, dependencies=["outline"]))
# 执行
results = await executor.execute()
# 输出结果
for task_id, result in results.items():
print(f"{task_id}: {result.status.value} - {result.duration:.2f}秒")
if __name__ == "__main__":
asyncio.run(main())八、错误处理与重试
8.1 重试策略
from functools import wraps
import time
import random
class RetryStrategy:
"""重试策略"""
def __init__(self, max_retries=3, base_delay=1, max_delay=60, exponential=True):
self.max_retries = max_retries
self.base_delay = base_delay
self.max_delay = max_delay
self.exponential = exponential
def get_delay(self, attempt: int) -> float:
"""计算重试延迟"""
if self.exponential:
delay = self.base_delay * (2 ** attempt)
else:
delay = self.base_delay * attempt
# 添加随机抖动
jitter = random.uniform(0.5, 1.5)
delay = delay * jitter
return min(delay, self.max_delay)
def with_retry(strategy: RetryStrategy = None):
"""任务重试装饰器"""
if strategy is None:
strategy = RetryStrategy()
def decorator(func):
@wraps(func)
async def wrapper(*args, **kwargs):
last_exception = None
for attempt in range(strategy.max_retries + 1):
try:
return await func(*args, **kwargs)
except Exception as e:
last_exception = e
if attempt < strategy.max_retries:
delay = strategy.get_delay(attempt)
print(f"任务失败,{delay:.1f}秒后重试({attempt + 1}/{strategy.max_retries})")
await asyncio.sleep(delay)
else:
print(f"任务失败,已达最大重试次数")
raise last_exception
return wrapper
return decorator
# 使用
@with_retry(RetryStrategy(max_retries=3, base_delay=2))
async def unreliable_task(inputs):
"""可能失败的任务"""
import random
if random.random() < 0.7: # 70%概率失败
raise ValueError("随机失败")
return {"result": "成功!"}九、最佳实践
9.1 设计原则
任务粒度要适中。太粗的话并行度低,太细的话调度开销大。一般建议单个任务执行时间在1-60秒之间。
避免单点失败。编排系统本身不能是单点故障。任务执行器要有容错机制,工作流状态要持久化。
做好监控告警。任务执行时间、成功率、资源使用情况都要监控。异常要及时告警。
设计要预留扩展。新需求来的时候最好只需要添加新任务,而不是修改已有任务或工作流结构。
9.2 性能优化
批量处理:如果多个任务都访问同一个数据源,考虑合并成一次批量读取。
连接复用:数据库、网络请求等连接要复用,减少连接开销。
智能缓存:如果某个任务的输入没变,输出应该可以直接用缓存。
资源隔离:重量级任务和轻量级任务分开执行,避免互相影响。
9.3 检查清单
□ 工作流设计
□ 任务分解合理,粒度适中
□ 依赖关系清晰,无循环依赖
□ 关键路径已识别
□ 容错机制
□ 重试策略已配置
□ 超时时间已设置
□ 失败处理已定义
□ 可观测性
□ 任务状态已记录
□ 执行时间已统计
□ 告警规则已配置
□ 性能
□ 并发数已设置
□ 批量处理已优化
□ 连接复用已实现十、总结
任务编排是复杂AI应用的基础设施。当你的应用有多个Agent、多个步骤、多条路径时,编排系统让这一切有序运转。
DAG是最核心的数据结构。理解DAG的特性和执行方式,是掌握任务编排的关键。
错误处理要提前设计。不要等问题发生了才想怎么处理,要提前规划重试、降级、跳过等策略。
监控比开发更重要。上线后的可观测性决定了你能多快发现问题、定位问题。
延伸阅读
- Apache Airflow:成熟的工作流平台
- Dagster:现代数据编排框架
- Prefect:Python优先的工作流框架
课后练习
基础题:设计一个三任务的工作流:A查资料、B处理数据、C输出结果。A和B可并行,C依赖A和B。
进阶题:实现一个带重试和超时的工作流执行器,支持最多3次重试,每次重试延迟指数增长。
挑战题:实现一个动态工作流,根据任务执行结果动态决定下一步执行哪个任务。