


刚刚,月之暗面扔出一颗深水炸弹。
2026年6月12日,Kimi正式发布并开源Kimi K2.7 Code编程模型。参数量1.1万亿,上下文窗口256K。更重要的是,这款模型终于解决了一个困扰行业很久的问题——AI在长程任务中的”过度思考”。
Token消耗直降30%。这意味着什么?意味着你让它写一个大型项目,它不会再先写10万字的”思考过程”再动笔,而是直接干活。
💡 Kimi选择在这个时间点开源一款编程模型,背景值得琢磨。GPT-5.5和Claude Opus 4.8已经在编程赛道形成压制,K2.7 Code的出现,是防守,也是试探。
一、1.1万亿参数背后:这次迭代解决什么问题
K2.7 Code不是大版本,而是一次精准的补丁。
前代K2.6的问题在于:长上下文场景下,模型的推理链路太长,每次处理复杂任务都会消耗大量Token。”想太多”导致成本高、速度慢,用户体验很差。
K2.7 Code的改进方向很明确:
💡 第一,降低Token消耗。 平均减少30%,不是通过压缩模型实现,而是优化推理路径。模型学会了在合适的时候”停止思考,直接动手”。
💡 第二,提升指令遵循能力。 编程任务往往有复杂的需求描述,K2.6在长程任务中容易丢失关键约束。K2.7 Code的指令遵循能力显著增强。
💡 第三,改善过度思考。 这是核心卖点。月之暗面在发布会上没有回避这个问题,甚至专门花大篇幅解释”什么是过度思考、为什么它会影响用户体验”。
💡 把问题坦诚说出来再解决,比PPT上写”性能大幅提升”要诚实得多。
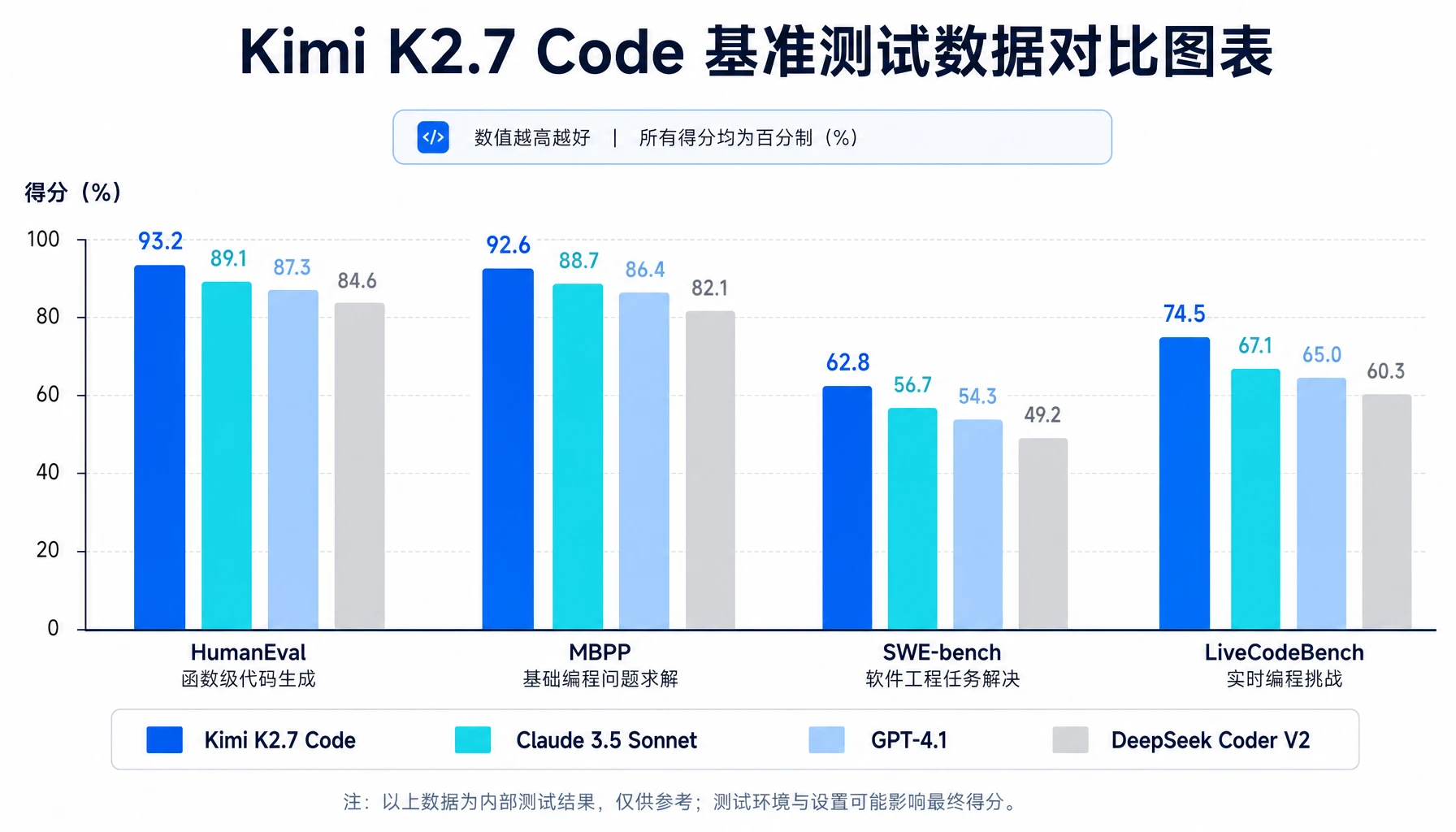
二、基准测试:60分,距离GPT-5.5还有差距
发布会上最值得关注的细节是:月之暗面主动公布了与GPT-5.5和Opus 4.8的对比差距。
不是”我们超越了XXX”,而是”我们和顶级模型还有差距”。
具体数据:如果GPT-5.5和Opus 4.8在编程上做到70分,K2.6大约是50分,K2.7 Code提升到了60分以上。
这是一个诚实的分数。K2.7 Code在多项专业基准测试中表现如下:
| 基准测试 | 提升幅度 |
|---|---|
| Kimi Code Bench v2 | +21.8% |
| Program-Bench | +11% |
| MLS Bench Lite | +31.5% |
| Kimi Claw 24/7 Bench | +10% |
| MCP Atlas | +10% |
| MCP Mark Verified | +10% |
从50分到60分,进步是真实的。但月之暗面没有用”局部超越”的话术包装,而是把完整数据摊开。这种态度在国内AI圈不多见。
💡 Kimi选择在发布会上”坦白差距”,而不是用局部数据夸大宣传。这种做法在国产大模型中不多见,也正因为如此,反而更值得关注。
三、实测:做前端、搭”智能体小镇”,K2.7 Code表现如何
智东西第一时间进行了实测。
💡 测试一:macOS风格前端demo
任务是让K2.7 Code用单个HTML文件复刻一个macOS风格的操作系统demo,包含开机动画、便签、浏览器等基本功能。
结果:K2.7 Code的响应速度明显快于前代。模型”更果断”——在简单任务上不再反复自我质疑、长篇大论地思考然后再动手。由于生成耗时短,迭代速度也更快。
最终效果:demo完成度不错,开机动画、基本功能都能正常运行。不足的是SVG开机动画与苹果logo过于相似,多次要求修改后仍未有明显改善。
💡 测试二:”智能体小镇”开发
智能体小镇(Agent Town)是斯坦福大学与谷歌合作推出的多智能体交互实验项目。测试中,K2.7 Code先输出了一份PRD文档,包含产品定位、市场背景、功能架构、技术方案等细节。
然后在PRD指导下开发最小可行版本(MVP)。one-shot生成结果存在一些bug,画面无法正常渲染。经多次迭代优化,30分钟后交付了完整可用版本。接入大模型后可正常与智能体对话。
💡 AI编程模型的迭代速度正在无限逼近”人类程序员的速度”。当模型学会果断行动而非反复思考,效率提升是指数级的。
四、定价:和K2.6一致,高速版6月15日上线
K2.7 Code已上线Kimi API开放平台,定价与K2.6保持一致:
| 类型 | 价格 |
|---|---|
| 标准输入(1M token) | 6.5元 |
| 标准输出(1M token) | 27元 |
| 缓存命中输入 | 1.3元 |
Kimi Code Plan的默认模型已同步升级为K2.7 Code。值得注意的是,使用K2.7 Code必须开启思考模式。如果手动关闭思考模式,API会报错,Kimi Code会自动回退到K2.6。
这是一个有趣的设定:月之暗面认为K2.7 Code的最佳性能必须依赖思考模式。这也意味着,”无脑快”不是这款模型的追求,”聪明地快”才是。
💡 思考模式强制开启是一个明确的信号:K2.7 Code不是要取代K2.6,而是在编程这个细分场景做到极致。非编程任务,K2.6仍然是首选。
下周一(6月15日),Kimi K2.7 Code高速版将开放调用。输出速度约为普通版的5-6倍:
- 常规编程场景:约180 Token/s
- 短上下文场景:最高260 Token/s
- 价格:普通版的2倍
这是一个明确的产品分层策略。普通版满足日常需求,高速版为高强度编程场景准备。
五、为什么月之暗面要开源这款模型
K2.7 Code是月之暗面第一次在编程模型上开源。
背后的逻辑值得思考。GPT-5.5和Opus 4.8已经在编程赛道建立了明确的优势,Kimi选择用开源的方式切入,是希望快速积累开发者生态和真实场景反馈。
开源的好处是双重的:
💡 第一,建立开发者信任。 开发者可以本地测试、可以验证基准数据、可以提出issue。这种透明度的回报是社区参与度。
💡 第二,加速能力迭代。 开源社区的反馈往往比内部测试更能暴露模型问题。月之暗面显然希望借助社区力量快速迭代K2.7 Code的能力边界。
💡 开源一款编程模型,本质上是在编程场景和OpenAI、Anthropic正面竞争。开发者生态的争夺,才是这场发布真正的战场。
六、K2.7 Code和K2.6怎么选
月之暗面给了一个很清晰的使用指南:
- 💡 编程任务、Agent任务 → 选K2.7 Code
- 💡 非编程的综合任务 → 选K2.6
这两款模型不是替代关系,而是分工关系。K2.6是全能型选手,K2.7 Code是编程赛道的专项选手。
如果你主要用Kimi处理文案、问答、分析等任务,K2.6仍然是主力。如果你从事软件开发、需要处理复杂的长程编程任务,K2.7 Code会带来明显的效率提升。
💡 术业有专攻,大模型也在走向专业化。K2.7 Code的出现,是大模型从”通用”走向”垂直”的一个缩影。
七、K3才是今年的重头戏
发布会上有一个容易被忽略的细节:月之暗面透露,K3才是今年的重头戏。
K2.7 Code是一次精准的补丁迭代,目标是巩固编程赛道的既有优势。而K3的提升”将会很明显”,目标是与GPT-5.5、Opus 4.8正面竞争。
从50分到60分,K2.7 Code用了不到一年。K3能否突破70分,决定了国产大模型能否真正站上编程赛道的顶峰。
八、国产大模型的”坦诚时刻”
整场发布会最值得记录的不是K2.7 Code的参数或基准数据,而是一种态度。
月之暗面没有找某个评测项目去证明自己”超越了GPT-5.5″。相反,他们主动公布了差距,解释了原因,展示了目标。
这种坦诚在国内AI圈并不常见。很多公司发布大模型,喜欢挑一两个评测项目证明自己”全球领先”,但真实能力如何,只有自己知道。
Kimi的选择是:承认差距,然后努力追赶。
💡 Kimi这场发布会的真正价值,不在于K2.7 Code本身,而在于它示范了一种可能的路径:与其在PPT上超越,不如在产品上逼近。
九、参考资料
- Kimi官方发布公告(2026年6月12日)
- 智东西实测报道(2026年6月12日)
- 快科技《国产大模型Kimi 2.7 Code发布》(2026年6月12日)
- 太平洋电脑网《Kimi K2.7 Code高速版即将上线》(2026年6月12日)
- IT之家《月之暗面开源Kimi K2.7 Code编程模型》(2026年6月12日)



我要评论