


国产AI算力迎来最关键一战。
2026年5月,一组数据震动了整个AI行业。根据OpenRouter最新发布的模型月榜,DeepSeek旗下三款模型集体闯入前十:V4 Flash以9.13万亿tokens的月调用量稳居榜首,V4 Pro达3.89万亿排第九,V3.2为4.07万亿排第八——三者累计调用量突破17万亿tokens。
这不是孤例。排名前两位的Hermes Agent和OpenClaw,月调用量分别达到了10.8T和6.25T tokens。
换句话说,如今Token消耗的绝对主力,已经从传统的聊天机器人,彻底让位给了会规划、检索、调用工具并反复验证的Agent系统。它就像一个小型工作流,单次任务动辄触发上百轮LLM调用,并伴随数十次工具执行,再加上长记忆和自演进产生的数据,负载常常飙升至数百GB甚至TB级。
这种以「万亿」为单位的高强度并发,正在将底层基础设施的每一个短板无限放大。
一、Agent时代:Token消耗的游戏规则变了
回望过去两年,大模型的竞争焦点长期集中在「对话」场景——聊天机器人、智能客服、文本生成,这些应用的Token消耗虽然大,但模式相对简单:用户输入一段文字,模型输出一段回复,单次交互的Token量可以估算。
Agent彻底改变了这个逻辑。
当一个AI开始规划任务、调用工具、执行多步骤工作流时,它的Token消耗呈现出完全不同的特征:
第一,多轮调用叠加。一个Agent任务可能被拆解为数十个子步骤,每一步都需要LLM推理,每一步都会产生输入Token和输出Token。单个用户请求最终可能触发上百次模型调用。
第二,长上下文成为标配。RAG(检索增强生成)场景下,Agent需要读取大量文档片段作为上下文;多轮对话场景下,历史消息的全部内容都需要参与推理。百万token的上下文窗口正在从「高端配置」变为「基本需求」。
第三,工具调用产生额外开销。每一次API调用、每一次数据库查询、每一次文件读写,都伴随着身份验证、数据序列化、网络传输等隐性Token消耗。
第四,自演进数据不断累积。成熟的Agent系统会保存用户偏好、任务历史、中间结果,这些数据在下一次任务中被加载、使用,形成持续增长的内存开销。
这种以「万亿」为单位的高强度并发,正在将底层基础设施的每一个短板无限放大。 而这,恰恰是国产AI算力面临的历史性考验。
二、昇腾的通用答卷:不是专有适配,是提前卡位
2026年4月,国产大模型迎来了一个重要节点:智谱GLM-5.1、MiniMax M2.7、DeepSeek V4三个头部模型密集开源,而它们有一个共同的技术特征——昇腾Atlas系列做到了「发布即支持」。
这并非偶然。
几个月前,坊间曾流传过一个似是而非的猜测:DeepSeek V4发布有所推迟,是因为在与昇腾做底层的深度适配。这引发了一种错觉,让人以为昇腾正在成为某一家大模型厂商的「专有硬件」。
这恰恰是对算力底座和模型演进关系最大的误解。
DeepSeek V4之所以能做到「开箱即优」,并不是昇腾为了某款模型削足适履,而是因为LLM演进到今天,必然会撞上这几堵墙——而昇腾,只是恰好提前在那里等它。
放眼中国大模型的第一梯队,不管智谱、MiniMax,还是引爆全网的DeepSeek,尽管微观算法、应用场景千差万别,但在迈向「低精度量化、长上下文、万亿MoE」这几个方向时,步调是一致的。
面对整条赛道的共性需求,昇腾交出的是一套通用的答卷。能做到这种覆盖速度,唯一解释是其底层能力高度通用。
三、万亿MoE通信墙:MegaMoE融合算子
MoE(混合专家)架构是当前顶级大模型的共同选择。它的核心优势是每次只激活一小部分专家来干活,计算效率极高。但代价同样明显:专家分散在不同的卡上,每次推理都要大量卡间通信。

当模型规模达到万亿级,通信成为比计算更棘手的瓶颈。
昇腾之前已有的MC2通算融合算子,在不同的并行方式下把矩阵计算和集合通信做了融合。然而在EP并行模式下,现有算子仍无法实现通信与Grouped Matmul计算的完全并行,并未达到真正的通算融合。
MegaMoE补上的,正是这个缺口。
它把MoE推理中原本分开执行的五个步骤——Alltoall Dispatch、GMM1、Swiglu、GMM2、Alltoall Combine——融合成一个大算子,让通信和计算尽可能同时进行,同时支持Prefill和Decode场景。
昇腾Atlas 800 A3上的实测数据显示,DeepSeek V3.1和Qwen3-235B两个模型接入MegaMoE融合算子后,Prefill场景获得20%到30%的性能提升,Decode场景也有10%以上的收益。
这意味着什么?万亿级MoE模型的通信瓶颈,被一个算子打通了。
四、百万上下文:先过内存这一关
如果说MoE的挑战是通信,那么百万token上下文的挑战则是内存。
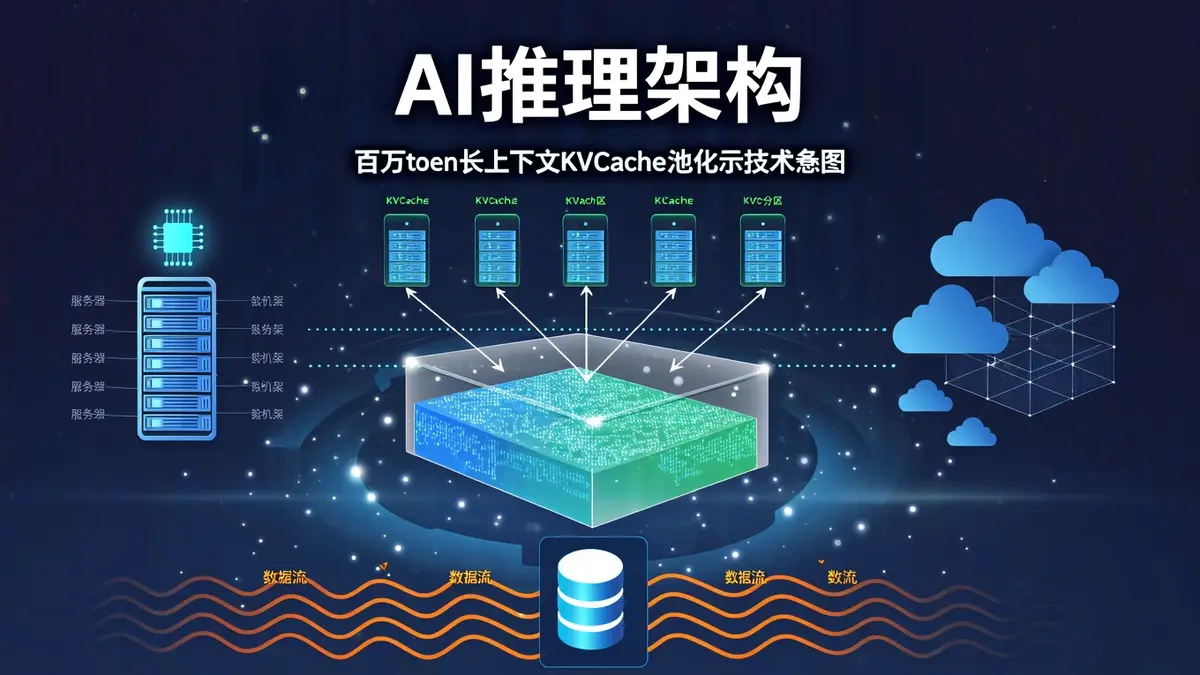
Prefix Cache(前缀缓存)是当前大模型推理服务中广泛使用的优化技术。它通过缓存多轮对话或长文档中重复出现的前缀部分的KVCache,让新请求可以跳过这部分的重复计算,从而降低首Token时延、提升整体吞吐。多轮对话、RAG、Agent场景都离不开它。
但单机Prefix Cache有一个根本局限:缓存只存在本机本地内存里,容量有限,容易被淘汰。更关键的是,跨机器的实例之间完全不共享——集群越大,缓存利用率反而越低。
而多机部署、PD分离、大规模专家并行,恰恰是所有万亿级MoE模型的标准部署方式,它们都对多机间的内存共享和数据调度提出了更高要求。
昇腾提出了全新的KVCache池化方案:框架层通过KV Connector对接池化后端,去除冗余的三方转发层,让多机共享成为可能。
与此同时,长序列还有一个更底层的压力。Prefill阶段的计算量随序列长度呈平方级增长,Decode阶段的KVCache内存占用则随序列长度线性增长——长序列同时带来计算和内存的双重瓶颈。
昇腾采用PCP做Prefill阶段的算力切分,DCP做Decode阶段的KVCache内存切分,两者配合把双重压力同时分摊开。实测数据显示,这套方案让Agentic场景下的Prefill性能提升4倍以上,并且不限于某一个模型,任何需要百万级上下文的场景都能受益。
当超长上下文逐渐变成「基本需求」,长序列的基础设施能力,已经是开发者选择平台时绕不开的一道题。
五、低精度量化:难的不是压缩,是可靠
通信和内存之外,精度是第三个绕不过去的难题。
传统量化方式(INT4/INT8/FP8)用全局统一缩放因子,相当于一把尺子量所有参数。碰到异常值,整个缩放范围就被拽偏了。
在参数分布差异极大的MoE模型中,这一问题尤为致命——某些专家的参数可能非常「奇葩」,用全局缩放因子去量化它们,要么精度损失严重,要么不得不保留更高的位数来维持效果。
为了解决这个矛盾,行业正在向Microscaling格式(MXFP4/MXFP8)收敛。它的原理是把参数分成小组,每组用独立缩放因子,异常值只影响本组,不拖累全局。
但光有格式标准还不够,关键是硬件和工具链能不能跟上。
昇腾950系列在架构层面提供了专用的块缩放因子计算单元和MXFP矩阵乘法加速器,从硬件层原生支撑MX格式。再往上,MindStudio工具支持一键生成MXFP4/MXFP8模型权重,开发者不需要手动处理量化细节。
从硬件到工具链全部打通之后,任何想走MXFP路线的模型,在昇腾上都能快速适配。
六、格局重塑:Agent时代的基础设施之争
从低精度量化到长序列池化,再到MoE通算融合,这三个方向看似各自独立,但背后对应的是同一个命题:
Agent时代的推理基础设施该怎么建?
传统的AI基础设施围绕「单次推理」设计,核心指标是单次调用时延和并发量。但Agent的工作模式完全不同——它需要持续多轮推理、实时工具调用、海量上下文管理,这些需求叠加在一起,对基础设施提出了完全不同的要求。
具体来说,Agent对基础设施的挑战体现在三个层面:
第一,持续性高负载。不同于聊天机器人的「一问一答」,Agent处理一个任务可能需要数分钟甚至数小时,其间持续消耗Token,这对算力集群的稳定性和可持续性提出了极高要求。
第二,异构工具调用。Agent不仅要调用大模型,还要调用搜索引擎、数据库、代码解释器等各种工具,每一次工具调用都伴随着数据序列化和网络开销,这些「间接成本」在传统AI负载中几乎不存在。
第三,内存墙问题。当一个Agent同时处理上百个用户请求,每个请求都带着MB级的上下文,内存带宽和容量很快成为瓶颈。传统架构下,内存墙问题在单次推理中尚不明显,但Agent的长生命周期让它暴露无遗。
这不是某一家芯片厂商能独立回答的问题,而是整个国产AI生态面临的共同考题。
在这个命题上,昇腾全系列产品不仅已经实现了对DeepSeek的全面支持,更让人看到了V4背后的一条完整链路:从底层芯片、底层编程语言到核心算子,关键环节都有中国自己的方案。
可以说,DeepSeek V4的出现,印证了中国已经可以依靠一整套自主创新的生态体系来打造顶尖大模型。 而昇腾,正是这条生态链路上的算力底座,一个面向全行业的通用AI软硬件平台。
Agent时代的推理负载还在膨胀,下一个万亿级模型随时会来。这个平台能接得住的,远不止DeepSeek。
你觉得,国产AI算力能在Agent时代实现全面超越吗?欢迎在评论区分享你的观点。



我要评论