【高级应用】Day12:特定领域模型定制–金融/医疗/法律垂直领域实战

章节导语
通用模型在医疗、法律、金融等专业领域往往力不从心。不是AI不够聪明,而是这些领域有独特的术语、规则和逻辑,通用数据里根本没学过。
垂直领域定制,就是让AI真正”懂行”。不是简单喂几篇文档就完事了,而是要从知识体系、术语规范、合规要求等多个维度系统性地改造。
本文系统讲解金融、医疗、法律三大领域的AI定制方案,包括领域知识库构建、术语处理、合规检查等实战内容。每个领域都有完整代码,帮助你快速落地。
为什么要学垂直领域定制?因为通用AI在专业场景的表现往往不尽如人意。一个经过领域定制的AI,专业度可以接近行业专家,而成本只是专家的零头。但定制的过程不是简单调用API,而是要深入理解领域知识体系、监管要求、用户场景。
本文的核心观点:垂直领域定制的成功,30%靠模型,70%靠数据。模型架构再先进,没有高质量的领域数据,也做不出好的垂直应用。
一、前置说明
1.1 学习路径
| 阶段 | 内容 |
|---|---|
| 基础 | RAG(Day8)、Fine-tuning(Day13) |
| 进阶 | 垂直领域定制 |
1.2 读者需要的基础
- RAG开发:会构建知识库、知道检索增强生成
- Fine-tuning:了解微调基本概念
- Python基础:能处理文本数据
1.3 学习目标
学完本文,你将能够:
- 理解垂直领域定制的核心挑战
- 构建金融/医疗/法律领域的知识库
- 实现领域术语识别和处理
- 设计领域合规检查系统
- 综合运用RAG+微调+合规检查
二、垂直领域定制的挑战
2.1 核心挑战分析

垂直领域和通用领域最大的差异,不是模型不够好,而是数据分布不同。
第一,术语壁垒。医疗说”高血压”,通用模型可能理解成”压力很高”。法律说”善意取得”,通用模型可能完全不知道这是什么。这些专业术语,在通用数据里出现频率很低,模型学得不好。
第二,知识壁垒。医学指南年年更新,法律条文经常修订。这些最新知识,通用模型的训练数据里根本没有。用通用模型回答专业问题,往往是过时的或者错误的。
第三,合规要求。金融不能预测具体股价,医疗不能给出诊断,法律不能冒充律师执业。这些限制不是技术问题,但处理不好会让产品没法上线。
第四,准确性要求。通用模型有时候会”一本正经地胡说八道”,这在娱乐场景问题不大,但在医疗、法律场景可能害人害命。
2.2 三大领域特点对比
| 领域 | 核心挑战 | 数据来源 | 合规重点 |
|---|---|---|---|
| 金融 | 数据密集、法规多、时效性强 | 年报、研报、法规、新闻 | 投资建议合规、风险提示 |
| 医疗 | 术语复杂、涉及生命安全 | 指南、文献、病历、药品说明 | 诊断建议限制、处方资质 |
| 法律 | 条文繁多、逻辑严密、地域差异 | 法规、司法解释、判例 | 执业资格限制、律师替代禁止 |
三、金融领域定制
3.1 金融知识库构建
金融领域的数据有几大特点:时效性强(昨天的政策今天可能变了)、术语密集(PE、ROE、MACD等专业术语)、格式规范(年报、公告有固定格式)。
构建金融知识库,需要解决几个问题:
第一,数据源整合。年报来自公开披露,研报来自券商,法规来自监管部门。这些数据源不同,格式不同,需要统一处理。
第二,术语标准化。同样的指标可能有不同说法,比如”市盈率”也叫”PE”、”本益比”。需要建立术语词典,统一检索。
第三,时效性管理。金融政策随时可能变化,知识库里的内容需要标注时间,过时的信息要能识别。

3.2 金融合规检查
金融领域的输出有严格的合规要求。不是技术问题,是监管要求。
禁止性表述包括:不能预测具体价格(”会涨到XX元”)、不能保证收益(”稳赚不赔”)、不能夸大收益(”翻倍”)。
必须包含的内容包括:风险提示(”投资有风险”)、免责声明(”仅供参考,不构成投资建议”)。
这些要求不是建议,是监管强制要求。违规的AI产品可能面临监管处罚。
3.3 财报解读助手实战
金融领域最典型的应用是财报解读。输入一份年报,输出关键数据和解读。
核心能力要求:能读懂财务报表、计算关键指标、与行业对比、给出风险提示。
技术方案:RAG用于检索最新法规和行业数据,微调用于优化财报解读的专业语气,合规检查用于过滤违规表述。
四、医疗领域定制
4.1 医疗知识库构建
医疗领域的数据复杂程度更高,主要体现在:
第一,术语体系庞大。ICD-10有约14000个疾病代码,药品名称更是数以万计。还有检验指标、医学影像描述等专业术语。
第二,指南更新频繁。临床指南每年都在更新,新的治疗方案、新的药物不断出现。知识库必须能及时更新。
第三,多模态需求。医学影像、检验报告等非结构化数据也需要处理。

4.2 医疗合规检查
医疗领域的合规要求更严格,核心是不能提供诊断和处方。
禁止性表述:不能诊断疾病(”你得了XX病”)、不能建议用药(”吃这个药”)、不能预测预后(”肯定能治好”)。
原因:医疗问题太专业,AI的判断可能有误,而医疗错误可能危及生命。
正确做法:提供健康信息,提示就医,让用户自己做决定。
医疗AI的定位应该是健康助手,而不是医生替代。
4.3 医患对话助手实战
医疗领域最典型的应用是预问诊分诊。用户描述症状,AI整理信息帮助用户理清思路,同时生成结构化的病情摘要供医生参考。
核心能力要求:症状收集、病历整理、就医指引、健康教育。
技术方案:RAG用于检索最新临床指南,微调用于优化医患对话语气,合规检查用于过滤诊断性表述。
五、法律领域定制
5.1 法律知识库构建
法律领域的数据有其特殊性:
第一,条文优先。法律回答必须有明确的法条依据,不能凭空编造。”根据《民法典》第XX条”这样的表述在法律文本中非常重要。
第二,地域差异。不同地区的法规可能有差异,比如各地的消费投诉规定可能不同。知识库需要能区分地域。
第三,判例参考。法律不仅看条文,还要看实际判例。判例能帮助理解条文在实际中如何应用。

5.2 法律合规检查
法律领域的合规核心是不能冒充律师。
禁止性表述:不能给出具体法律建议(”你应该起诉”)、不能预测诉讼结果(”法院会判你赢”)、不能以律师身份回答。
正确做法:提供法律知识普及,告知用户应有的权利,建议咨询专业律师。
定位:法律知识助手,不是律师替代品。
5.3 法律咨询助手实战
法律领域最典型的应用是法律知识科普和文书指引。用户问一个法律问题,AI给出一般性的法律知识,而不是具体的诉讼建议。
核心能力要求:法条检索、类似判例参考、法律流程指引、文书模板提供。
技术方案:RAG用于检索法条和判例,微调用于优化法律文风的严谨性,合规检查用于过滤具体建议性表述。
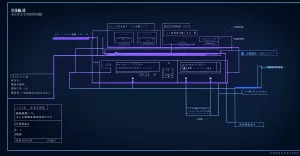
六、综合领域定制框架
6.1 领域定制架构设计
不同领域的定制方案有共同框架,只是具体实现不同。理解这个通用框架,有助于你快速迁移到其他领域。
在设计垂直领域AI系统时,有几个实践中的关键问题需要考虑:
第一个问题:知识库怎么建?领域知识库的来源是关键。公开数据如法规条文、指南文件容易获取,但高质量的内部数据往往很难得到。以医疗为例,临床指南公开可得,但真实的病历数据因为隐私问题无法使用。所以往往需要用公开数据做基础,再用少量高质量内部数据做微调。
第二个问题:模型选型怎么定?不是越大越好。金融合约分析场景,7B参数的模型可能就够用,70B的模型反而慢且贵。但如果是复杂的法律文书分析,可能就需要更大的模型。选择模型要基于效果测试,而不是盲目追求参数规模。
第三个问题:合规怎么做?合规检查不能依赖模型自己的”判断”,因为模型可能犯错。应该用规则引擎做硬限制,模型只负责内容生成,合规检查独立运行。就像金融的风控系统,交易规则和模型输出是两套独立的系统。
不同领域的定制方案有共同框架,只是具体实现不同。
第一层:数据层。包括领域知识库、术语词典、历史问答数据。知识库要定期更新,术语词典要维护版本。
第二层:模型层。包括通用LLM + 领域微调。可以是LoRA微调,也可以是全量微调,取决于数据量和资源。
第三层:合规层。包括输入过滤(敏感词检查)、输出过滤(违规表述检查)、内容安全(有害内容识别)。
第四层:应用层。包括API服务、Prompt模板、输出格式化。
"""
通用领域定制框架
适用于金融、医疗、法律等垂直领域
"""
from abc import ABC, abstractmethod
class DomainCustomizer(ABC):
"""领域定制基类"""
@abstractmethod
def build_knowledge_base(self):
"""构建领域知识库"""
pass
@abstractmethod
def create_compliance_checker(self):
"""创建合规检查器"""
pass
@abstractmethod
def generate_safe_response(self, user_input: str, analysis: str) -> str:
"""生成安全响应"""
pass
class FinanceCustomizer(DomainCustomizer):
"""金融领域定制"""
def build_knowledge_base(self):
return FinanceKnowledgeBase()
def create_compliance_checker(self):
return FinanceComplianceChecker()
def generate_safe_response(self, user_input: str, analysis: str) -> str:
checker = FinanceComplianceChecker()
safe_analysis = checker.sanitize_output(analysis, "general")
return safe_analysis
class MedicalCustomizer(DomainCustomizer):
"""医疗领域定制"""
def build_knowledge_base(self):
return MedicalKnowledgeBase()
def create_compliance_checker(self):
return MedicalComplianceChecker()
def generate_safe_response(self, user_input: str, analysis: str) -> str:
checker = MedicalComplianceChecker()
safe_analysis = checker.filter_diagnosis(analysis)
return f"{safe_analysis}\n\n{checker.generate_safe_response('', user_input)}"
class LegalCustomizer(DomainCustomizer):
"""法律领域定制"""
def build_knowledge_base(self):
return LegalKnowledgeBase()
def create_compliance_checker(self):
return LegalComplianceChecker()
def generate_safe_response(self, user_input: str, analysis: str) -> str:
checker = LegalComplianceChecker()
safe_analysis = checker.check_legal_content(analysis)
if not safe_analysis['safe']:
analysis = "# 内容已被过滤\n" + checker.generate_disclaimer()
return analysis
使用示例中只需几行代码就能创建对应领域的Agent:
```python
# 创建金融领域Agent
finance_agent = DomainAgentFactory.create("finance")
# 创建医疗领域Agent
medical_agent = DomainAgentFactory.create("medical")
# 创建法律领域Agent
legal_agent = DomainAgentFactory.create("legal")
```七、金融知识库代码
7.1 金融知识库实现
import re
from typing import List, Dict
class FinanceKnowledgeBase:
"""金融领域知识库
金融领域特点:
- 大量专业术语(PE、ROE、MACD等)
- 法规更新频繁
- 数据要求准确性高
"""
def __init__(self):
self.documents = []
self.terminology = {} # 术语词典
def add_document(self, doc_type: str, content: str, metadata: Dict = None):
"""添加文档
doc_type: 年报/研报/法规/公告
"""
doc = {
'type': doc_type,
'content': content,
'metadata': metadata or {},
'extracted_terms': self._extract_terms(content)
}
self.documents.append(doc)
print(f"✅ 添加{doc_type}文档,字数{len(content)}")
def _extract_terms(self, text: str) -> List[str]:
"""提取金融术语"""
# 常见金融术语模式
patterns = [
r'\bPE\b', r'\bPB\b', r'\bROE\b', r'\bROA\b',
r'\bEPS\b', r'\bGDP\b', r'\bCPI\b', r'\bPPI\b',
r'\bMACD\b', r'\bKDJ\b', r'\bRSI\b',
r'\b并购\b', r'\bIPO\b', r'\b定增\b', r'\b回购\b'
]
terms = []
for pattern in patterns:
matches = re.findall(pattern, text)
terms.extend(matches)
return list(set(terms))
def search_by_term(self, term: str) -> List[Dict]:
"""按术语搜索相关文档"""
results = []
for doc in self.documents:
if term in doc['extracted_terms']:
results.append(doc)
return results
def build_term_glossary(self) -> Dict[str, str]:
"""构建术语表"""
glossary = {
"PE": "市盈率,每股价格/每股收益,衡量估值水平",
"PB": "市净率,每股价格/每股净资产",
"ROE": "净资产收益率,净利润/净资产,衡量盈利能力",
"ROA": "资产收益率,净利润/总资产",
"EPS": "每股收益,净利润/股数",
"GDP": "国内生产总值,衡量一个国家的经济规模",
"CPI": "居民消费价格指数,衡量通货膨胀",
"MACD": "指数平滑异同移动平均线,技术分析指标",
"并购": " mergers and acquisitions,企业扩张策略"
}
self.terminology.update(glossary)
return glossary
# 使用
if __name__ == "__main__":
kb = FinanceKnowledgeBase()
# 添加年报
kb.add_document("年报", """
公司2023年营收100亿元,净利润10亿元。
PE为15倍,PB为2倍,ROE达到18%。
计划进行重大并购重组。
""", {"year": 2023, "company": "某上市公司"})
# 添加研报
kb.add_document("研报", """
预计公司2024年EPS为1.5元,目标PE 20倍。
当前CPI处于低位,利好消费板块。
""", {"date": "2024-01"})
# 构建术语表
glossary = kb.build_term_glossary()
print(f"\n📖 术语表:")
for term, definition in glossary.items():
print(f" {term}: {definition}")
# 按术语搜索
results = kb.search_by_term("并购")
print(f"\n🔍 搜索'并购'相关文档:{len(results)}篇")八、金融合规检查代码
8.1 金融合规检查器
import re
from typing import List, Dict
class FinanceComplianceChecker:
"""金融合规检查器
金融领域的输出有严格的合规要求:
- 不能提供具体投资建议
- 风险提示必须完整
- 禁止预测具体价格
"""
def __init__(self):
self.violations = []
self.risk_keywords = [
r'\d+元.*必涨',
r'\d+元.*稳赚',
r'保证.*收益',
r'100%.*盈利',
r'翻倍',
r'涨停.*预测'
]
self.required_disclaimers = [
"投资有风险",
"仅供参考",
"不构成投资建议"
]
def check_investment_advice(self, text: str) -> Dict:
"""检查投资建议合规性"""
violations = []
# 检查禁止性表述
for pattern in self.violations:
matches = re.findall(pattern, text)
if matches:
violations.append(f"禁止表述: {matches}")
# 检查风险提示
has_disclaimer = any(d in text for d in self.required_disclaimers)
# 检查预测性表述
prediction_patterns = [
r'预计.*涨到.*元',
r'预测.*达到.*元',
r'目标价.*元'
]
predictions = []
for pattern in prediction_patterns:
matches = re.findall(pattern, text)
predictions.extend(matches)
return {
'violations': violations,
'has_disclaimer': has_disclaimer,
'predictions': predictions,
'passed': len(violations) == 0 and has_disclaimer
}
def generate_disclaimer(self, content_type: str = "general") -> str:
"""生成合规声明"""
if content_type == "stock":
return """
【风险提示】
本报告仅供参考,不构成投资建议。股市有风险,投资需谨慎。
请勿根据本报告进行任何投资决策。入市有风险,投资需谨慎。
""".strip()
elif content_type == "fund":
return """
【基金风险提示】
基金过往业绩不代表未来表现。
本金有可能亏损,请充分了解产品风险后再投资。
""".strip()
else:
return """
【免责声明】
本内容仅供参考,不构成任何投资建议。
投资有风险,决策需谨慎。
""".strip()
def sanitize_output(self, text: str, content_type: str = "general") -> str:
"""合规化输出"""
# 添加免责声明
disclaimer = self.generate_disclaimer(content_type)
# 如果没有免责声明,添加
if not any(d in text for d in self.required_disclaimers):
text = text + "\n\n" + disclaimer
return text
# 使用
if __name__ == "__main__":
checker = FinanceComplianceChecker()
# 测试:不合规的表述
bad_text = """
某股票预计涨到100元,目标价翻倍!
保证收益稳赚不赔。
"""
result = checker.check_investment_advice(bad_text)
print("不合规检查结果:")
print(f" 违规项: {result['violations']}")
print(f" 有免责声明: {result['has_disclaimer']}")
print(f" 通过: {result['passed']}")
# 测试:合规的表述
good_text = """
从技术面看,该股处于上升趋势。
仅供参考,不构成投资建议。
"""
result2 = checker.check_investment_advice(good_text)
print("\n合规检查结果:")
print(f" 违规项: {result2['violations']}")
print(f" 通过: {result2['passed']}")
# 生成合规输出
sanitized = checker.sanitize_output("一些分析内容", "stock")
print(f"\n合规化输出:\n{sanitized}")九、医疗知识库代码
9.1 医疗知识库实现
import re
from typing import List, Dict
class MedicalKnowledgeBase:
"""医疗领域知识库
医疗领域特点:
- 术语极其专业(ICD-10、药品名等)
- 涉及生命安全,准确性要求极高
- 诊断建议有严格限制
"""
def __init__(self):
self.documents = []
self.icd_codes = {} # ICD编码
self.drug_db = {} # 药品数据库
def add_guideline(self, guideline_type: str, content: str, metadata: Dict = None):
"""添加临床指南"""
doc = {
'type': guideline_type, # 指南/文献/药品说明
'content': content,
'metadata': metadata or {},
'extracted_entities': self._extract_medical_entities(content)
}
self.documents.append(doc)
print(f"✅ 添加{guideline_type}指南")
def _extract_medical_entities(self, text: str) -> Dict[str, List]:
"""提取医疗实体"""
entities = {
'symptoms': [], # 症状
'diseases': [], # 疾病
'drugs': [], # 药品
'procedures': [], # 手术/检查
'icd_codes': [] # ICD编码
}
# 简单关键词匹配(实际应该用NER模型)
symptom_keywords = ['疼痛', '发热', '咳嗽', '头痛', '乏力']
disease_keywords = ['糖尿病', '高血压', '冠心病', '肺炎', '肝炎']
drug_keywords = ['阿司匹林', '布洛芬', '二甲双胍', '胰岛素']
for kw in symptom_keywords:
if kw in text:
entities['symptoms'].append(kw)
for kw in disease_keywords:
if kw in text:
entities['diseases'].append(kw)
for kw in drug_keywords:
if kw in text:
entities['drugs'].append(kw)
# ICD-10编码模式
icd_pattern = r'[A-Z]\d{2}\.\d{1,2}'
entities['icd_codes'] = re.findall(icd_pattern, text)
return entities
def search_by_symptom(self, symptom: str) -> List[Dict]:
"""按症状搜索相关指南"""
results = []
for doc in self.documents:
if symptom in doc['extracted_entities'].get('symptoms', []):
results.append(doc)
return results
def search_interaction(self, drug1: str, drug2: str) -> str:
"""查询药品相互作用"""
# 简化实现
interactions = {
("阿司匹林", "华法林"): "增加出血风险",
("布洛芬", "阿司匹林"): "可能降低阿司匹林的心脏保护作用",
("二甲双胍", "胰岛素"): "需调整剂量,避免低血糖"
}
key = (drug1, drug2)
reverse_key = (drug2, drug1)
if key in interactions:
return interactions[key]
elif reverse_key in interactions:
return interactions[reverse_key]
else:
return "未发现明确相互作用"
# 使用
if __name__ == "__main__":
kb = MedicalKnowledgeBase()
# 添加指南
kb.add_guideline("糖尿病指南", """
糖尿病诊断标准:
- 空腹血糖≥7.0mmol/L
- 糖化血红蛋白≥6.5%
二甲双胍是首选药物。
合并心血管疾病可考虑GLP-1受体激动剂。
ICD-10: E11.9 (2型糖尿病)
""", {"version": "2023", "source": "中华医学会"})
# 按症状搜索
results = kb.search_by_symptom("多饮")
print(f"搜索'多饮'相关指南:{len(results)}篇")
# 查询药物相互作用
interaction = kb.search_interaction("阿司匹林", "华法林")
print(f"\n药物相互作用:{interaction}")十、法律知识库代码
10.1 法律知识库实现
import re
from typing import List, Dict
class LegalKnowledgeBase:
"""法律领域知识库
法律领域特点:
- 法规条文繁多、更新频繁
- 司法解释补充
- 判例参考价值高
"""
def __init__(self):
self.laws = [] # 法规
self.precedents = [] # 判例
self.interpretations = [] # 司法解释
def add_law(self, law_name: str, article_number: str, content: str):
"""添加法规条文"""
law = {
'name': law_name,
'article': article_number,
'content': content,
'effective_date': None,
'key_terms': self._extract_legal_terms(content)
}
self.laws.append(law)
print(f"✅ 添加{law_name}第{article_number}条")
def add_precedent(self, case_number: str, case_type: str, ruling: str, key_points: List[str]):
"""添加判例"""
precedent = {
'case_number': case_number,
'type': case_type,
'ruling': ruling,
'key_points': key_points
}
self.precedents.append(precedent)
print(f"✅ 添加判例{case_number}")
def _extract_legal_terms(self, text: str) -> List[str]:
"""提取法律术语"""
terms = []
# 常见法律术语
legal_terms = [
'合同', '违约', '侵权', '赔偿', '责任',
'故意', '过失', '连带责任', '解除', '无效'
]
for term in legal_terms:
if term in text:
terms.append(term)
return terms
def search_laws(self, query: str) -> List[Dict]:
"""搜索相关法规"""
results = []
query_terms = set(query)
for law in self.laws:
# 术语匹配
law_terms = set(law.get('key_terms', []))
if query_terms & law_terms:
results.append(law)
# 内容匹配
elif query in law['content']:
results.append(law)
return results
def search_precedents(self, case_type: str = None, key_point: str = None) -> List[Dict]:
"""搜索判例"""
results = self.precedents
if case_type:
results = [p for p in results if p['type'] == case_type]
if key_point:
results = [p for p in results if key_point in p['key_points']]
return results
# 使用
if __name__ == "__main__":
kb = LegalKnowledgeBase()
# 添加法规
kb.add_law("民法典", "第五百零二条", """
依法成立的合同,自成立时生效,但是法律另有规定或者当事人另有约定的除外。
""")
kb.add_law("民法典", "第五百七十七条", """
当事人一方不履行合同义务或者履行合同义务不符合约定的,应当承担继续履行、采取补救措施或者赔偿损失等违约责任。
""")
kb.add_law("民法典", "第一千一百六十五条", """
行为人因过错侵害他人民事权益造成损害的,应当承担侵权责任。
""")
# 添加判例
kb.add_precedent(
case_number="(2023)最高法民终123号",
case_type="合同纠纷",
ruling="构成违约,应承担赔偿责任",
key_points=["合同成立", "违约责任", "赔偿损失"]
)
# 搜索法规
results = kb.search_laws("违约责任")
print(f"\n🔍 搜索'违约责任'相关法规:{len(results)}条")
for r in results:
print(f" {r['name']}第{r['article']}条")
# 搜索判例
precedents = kb.search_precedents(case_type="合同纠纷")
print(f"\n🔍 合同纠纷判例:{len(precedents)}个")十一、总结与练习
11.1 垂直领域定制的实战经验
在实际项目中,垂直领域定制往往比想象中更复杂。这里分享几个实战经验:
经验一:数据准备比模型训练更花时间。一个典型的金融AI项目,80%的时间花在数据准备上:清洗历史对话、标注数据质量、整理知识库。模型训练和调参反而是相对快的环节。
经验二:合规检查要独立于模型。很多团队犯的错误是把合规检查寄托于Prompt工程,觉得只要Prompt写得好,模型就不会输出违规内容。但模型是不可控的,Prompt再严格也可能被绕过。正确的做法是用规则引擎做硬限制。
经验三:领域定制不是一次性工作。法规在更新、知识在演进、用户在变化。一个成功的垂直领域AI产品,需要建立持续运营的机制,包括数据更新、模型迭代、效果监控。
经验四:用户期望要管理好。用户容易把AI当成全能专家,但实际上垂直领域AI的能力有边界。在产品设计中要明确告知用户AI能做什么、不能做什么,避免用户过度依赖AI而导致风险。
经验五:效果评估要接地气。不是所有指标都越高越好。比如医疗AI的诊断准确率,如果为了追求数字好看而牺牲了召回率,可能漏诊更危险。评估指标的选择要基于业务场景的实际风险。
11.2 要点回顾
- 金融领域:术语密集、合规严格,投资建议限制多
- 医疗领域:诊断建议禁止、生命相关、安全第一
- 法律领域:执业资格限制、诉讼结果禁止预测
- 通用框架:知识库+RAG+微调+合规检查
11.2 合规要求对比
| 领域 | 禁止事项 | 必须声明 |
|---|---|---|
| 金融 | 预测具体价格、保证收益 | 投资有风险 |
| 医疗 | 诊断、处方、治疗建议 | 仅供参考,咨询医生 |
| 法律 | 具体建议、预测结果、冒充律师 | 不构成法律意见 |
11.3 延伸阅读
- 金融合规:证监会法规
- 医疗合规:《医疗机构管理条例》
- 法律合规:《律师法》
11.4 课后练习
基础题:为金融领域构建一个术语词典,包含至少20个常见术语。
进阶题:实现医疗领域的药品相互作用查询系统。
挑战题:构建一个通用的领域合规检查框架,支持自定义规则。